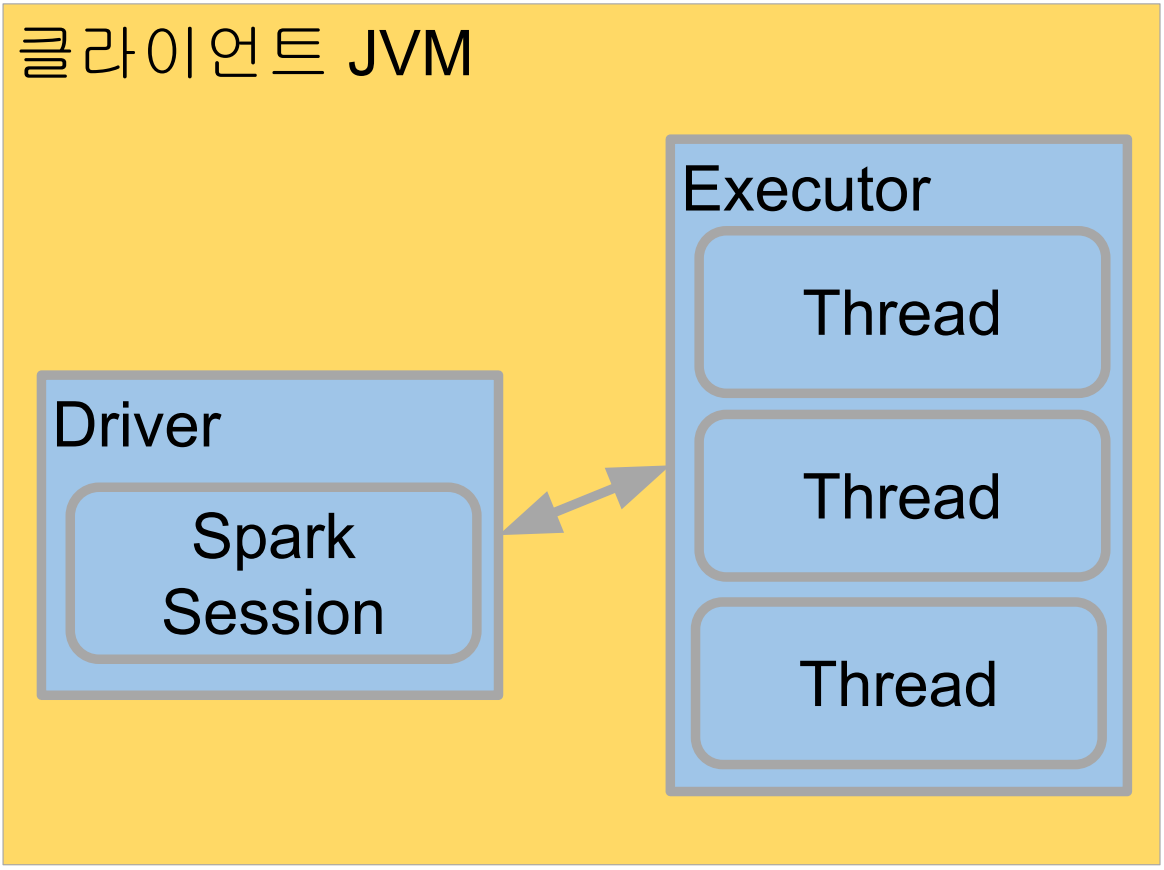
Contents 1. Spark 데이터 처리 2. Spark 데이터 구조: RDD, DataFrame, Dataset 3. 프로그램 구조 4. 개발/실습 환경 소개 5. Spark DataFrame 실습 개발/실습 환경 소개 Spark 개발 환경에 대해 알아보자 https://github.com/keeyong/beginner-spark-programming-with-pyspark/blob/main/spark/local_installation_windows.md 자바와 파이썬 설치여부와 버전 확인 java -version python --version 윈도우 10 + 기반 JDK11과 파이썬 3.8 혹은 그 이상을 설치 폴더 만들기 SPARK 3.0 설치 https://spark.apache.org/dow..