Contents
1. Spark 데이터 처리
2. Spark 데이터 구조: RDD, DataFrame, Dataset
3. 프로그램 구조
4. 개발/실습 환경 소개
5. Spark DataFrame 실습
개발/실습 환경 소개
Spark 개발 환경에 대해 알아보자
자바와 파이썬 설치여부와 버전 확인
java -version
python --version
윈도우 10 + 기반
JDK11과 파이썬 3.8 혹은 그 이상을 설치
폴더 만들기
SPARK 3.0 설치
https://spark.apache.org/downloads.html
Downloads | Apache Spark
Download Apache Spark™ Choose a Spark release: Choose a package type: Download Spark: Verify this release using the and project release KEYS by following these procedures. Note that Spark 3 is pre-built with Scala 2.12 in general and Spark 3.2+ provides
spark.apache.org

Note that Spark 3 is pre-built with Scala 2.12 in general and Spark 3.2+ provides additional pre-built distribution with Scala 2.13.
3번의 Donwload Spark의 링크를 클릭

위의 파일을 D:\Spark로 옮기고 압축해제를 한다.
Hadoop 설치
커다란 하둡을 본격적으로 설치하지는 않고 간단한 실습을 위한 것이므로 가벼운 대체용인 winutils를 설치하겠습니다.
https://github.com/cdarlint/winutils/blob/master/hadoop-2.7.7/bin/winutils.exe
다운 받고 여러분이 원하는 곳에 배치해주세요.
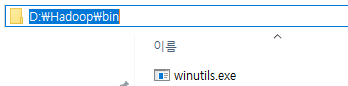
저는 D드라브의 Hadoop/bin 디렉토리에 배치했습니다.
환경변수 설정


시스템에서 고급 시스템 설정을 클릭하고
환경 변수를 선택한 뒤
시스템 변수 새로 만들기를 클릭
SPARK_HOME, HADOOP_HOME, JAVA_HOME 설정
HADOOP

SPARK
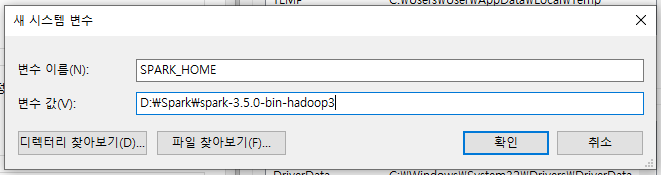
JDK는 JDK가 설치된 디렉토리에 맞춰 지정
PATH 수정

Path 선택 후 편집 클릭

%SPARK_HOME%\bin
%HADOOP_HOME%\bin
Path에 위의 두 개를 추가
spark 프로그램 실행
다음으로 D:\Spark 폴더 밑에서 spark-submit으로 pi.py를 실행한다
spark-submit --master local[4] ./spark-3.3.1-bin-hadoop3/examples/src/main/python/pi.py
만일 spark-submit이나 spark-shell이 작동하지 않느다면
1. JAVA_HOME 환경변수가 bin 경로까지 이어지지 않았는지
2. 환경변수에서 다음과 같이
변수이름: PYSPARK_PYTHON
변수 값: python
으로 지정을 한 뒤 CLI 창을 재시작한 뒤 작동 여부를 확인해주세요.
'하둡과 Spark' 카테고리의 다른 글
| Spark DataFrame 실습 2 (0) | 2024.01.17 |
|---|---|
| Spark DataFrame 실습 1 (0) | 2024.01.17 |
| Local Standalone REP 데모 - 맥(Mac) (0) | 2024.01.16 |
| 개발환경소개 Colab 설정과 코딩 데모 (0) | 2024.01.16 |
| Spark 프로그램 구조 (0) | 2024.01.16 |