
터칭 데이터
Spark DataFrame 실습 2 본문
Contents
1. Spark 데이터 처리
2. Spark 데이터 구조: RDD, DataFrame, Dataset
3. 프로그램 구조
4. 개발/실습 환경 소개
5. Spark DataFrame 실습
Spark DataFrame 실습
앞서 배운 내용들을 바탕으로 다양한 코딩 연습을 해보자
실습 2. 워밍업 2 - 헤더 없는 CSV 파일처리하기
입력 데이터: 헤더 없는 CSV 파일
https://s3-geospatial.s3-us-west-2.amazonaws.com/customer-orders.csv
데이터에 스키마 지정하기
cust_id, item_id, amount_spent를 데이터 컬럼으로 추가하기 (모두 숫자)
cust_id를 기준으로 amount_spent의 합을 계산하기
실습
Spark DataFrame으로 처리하기
pyspark와 py4j 설치
!pip install pyspark==3.3.1 py4j==0.10.9.5
SparkSession 객체 생성
from pyspark.sql import SparkSession
spark = SparkSession.builder\
.master("local[*]")\
.appName('PySpark DataFrame #2')\
.getOrCreate()
사용할 csv 파일 다운
!wget https://s3-geospatial.s3-us-west-2.amazonaws.com/customer-orders.csv
다운이 정상적으로 되었는지 확인
!ls -tltotal 148
drwxr-xr-x 1 root root 4096 Jan 12 19:20 sample_data
-rw-r--r-- 1 root root 146855 Apr 10 2022 customer-orders.csv
csv 파일의 상위 5개 레코드 확인
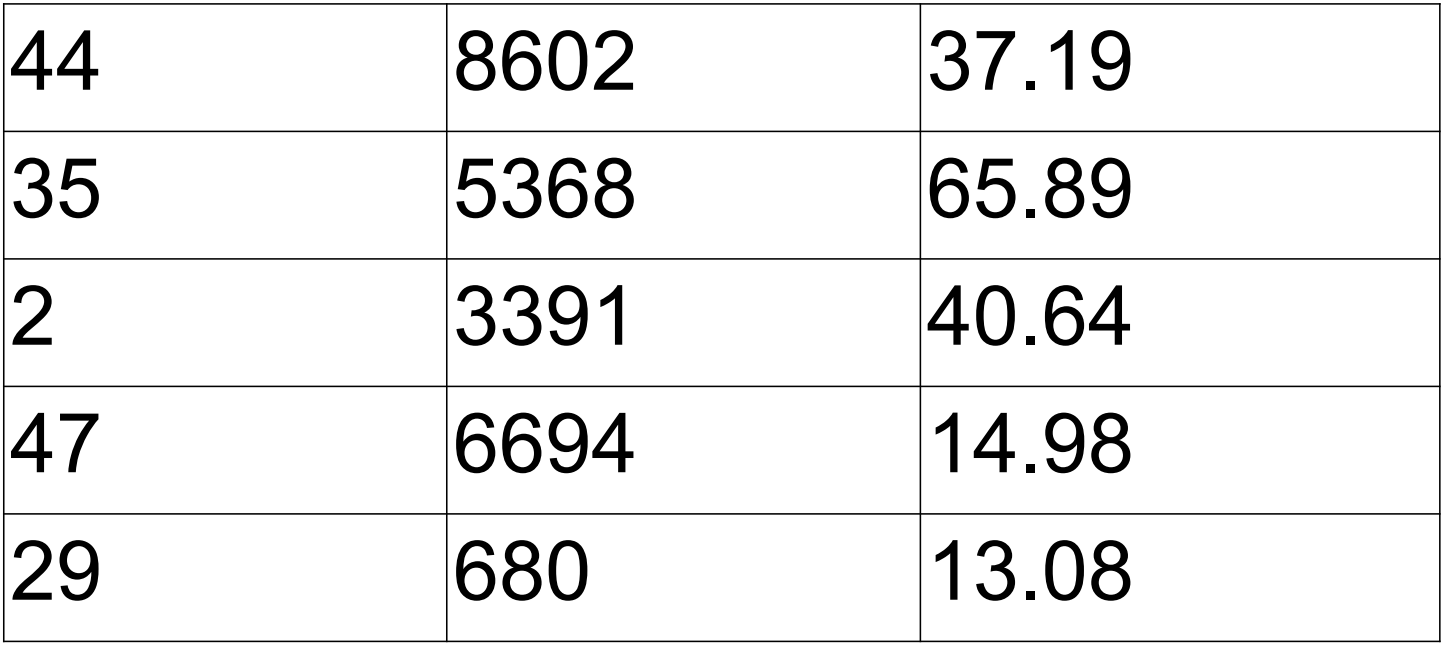
!head -5 customer-orders.csv44,8602,37.19
35,5368,65.89
2,3391,40.64
47,6694,14.98
29,680,13.08
컬럼의 이름과 타입을 StructType을 이용해 schema로 지정하기
from pyspark.sql import SparkSession
from pyspark.sql import functions as func
from pyspark.sql.types import StructType, StructField, StringType, FloatType
schema = StructType([ \
StructField("cust_id", StringType(), True), \
StructField("item_id", StringType(), True), \
StructField("amount_spent", FloatType(), True)])
df = spark.read.schema(schema).csv("customer-orders.csv")
df.printSchema()root
|-- cust_id: string (nullable = true)
|-- item_id: string (nullable = true)
|-- amount_spent: float (nullable = true)
df라는 Spark DataFrame을 로딩했습니다.
df_ca = df.groupBy("cust_id").sum("amount_spent")
cust_id 컬럼별로 amount_spent의 총량을 집계했습니다.
df_ca.show()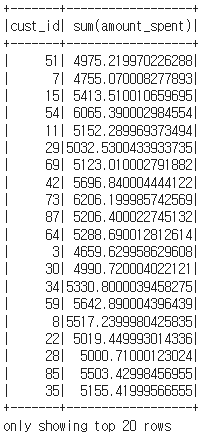
그런데 sum(amount_spent)라는 컬럼명을 바꾸고 싶습니다. 어떻게 해야 할까요?
2 가지 방법이 있습니다.
df_ca = df.groupBy("cust_id").sum("amount_spent").withColumnRenamed("sum(amount_spent)", "sum")
첫 번째는 빌드업 방식으로 withColumnRenamed 함수를 붙여 새로운 alias를 주는 방식이 있습니다.
df_ca.show(10)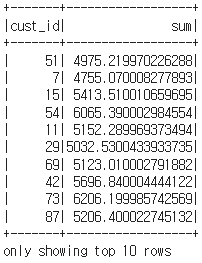
sum(amount_spent)가 조금 더 보기 좋게 sum으로 표시됩니다.
import pyspark.sql.functions as f
df_ca = df.groupBy("cust_id") \
.agg(f.sum('amount_spent').alias('sum'))
두 번째는 alias라는 함수를 사용하는 것입니다.
그런데 또 다른 점이 있습니다. 위에서는 groupBy이후 바로 sum 함수를 빌드업해 사용했지만 이번에는 agg 함수를 빌드업하고 인자로 pyspark.sql.functions(f)의 sum을 주었습니다. 이 방법이 더 편리한 방법입니다. 보통 aggregationi 함수를 하나만 사용하지 않기 때문입니다. 또 빌드업으로 계속 함수를 붙여가는 방식보다 가독성이 높기 때문입니다.
df_ca.show(5)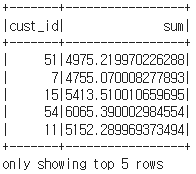
agg 함수 안에 한 번에 여러 집계함수를 사용할 수 있습니다.
df.groupBy("cust_id") \
.agg(
f.sum('amount_spent').alias('sum'),
f.max('amount_spent').alias('max'),
f.avg('amount_spent').alias('avg')).collect()
Spark SQL로 처리해보기
df.createOrReplaceTempView("customer_orders")df를 customer_order라는 테이블로 로딩합니다.
spark.sql("""SELECT cust_id, SUM(amount_spent) sum, MAX(amount_spent) max, AVG(amount_spent) avg
FROM customer_orders
GROUP BY 1""").head(5)
별 다른 함수 없이 간단하게 쿼리문으로 똑같이 cust_id별 sum, max, avg 값들을 구합니다.
구조화된 데이터를 처리할 때는 DataFrame보다 SparkSQL이 훨씬 더 간단하고 편리합니다.
메모리에 테이블을 하나 만든 셈입니다.
Spark은 기본으로 in-memory 카탈로그를 사용합니다. TEMPORARY가 아닌 persist한 스토리지 기반의 카탈로그를 쓰고 싶다면 SparkSession 설정할 때 enableHiveSupport()를 호출 (Hive metastore를 카탈로그로 사용하며 Hive UDF와 Hive 파일포맷 사용 가능)
spark.catalog.listTables()[Table(name='customer_orders', database=None, description=None, tableType='TEMPORARY', isTemporary=True)]
'하둡과 Spark' 카테고리의 다른 글
| Spark DataFrame 실습 4 (0) | 2024.01.18 |
|---|---|
| Spark DataFrame 실습 3 (4) | 2024.01.17 |
| Spark DataFrame 실습 1 (0) | 2024.01.17 |
| Local Standalone REP 데모 - 윈도우(Windows) (0) | 2024.01.16 |
| Local Standalone REP 데모 - 맥(Mac) (0) | 2024.01.16 |



