4. Kafka 기본 프로그래밍
Kafka로 데이터를 생성하고 소비하는 코드를 작성해보자
Contents
1. Client tool 사용
2. Topic 파라미터 설정
3. Consumer 옵션 살펴보기
4. ksqlDB 사용해보기
5. 숙제
Consumer 옵션 살펴보기
Consumer와 관계된 옵션들을 살펴보면서 Consumer Group에 대해서도 알아보자
KafkaConsumer 파라미터
Topic 이름을 KafkaConsumer의 첫 번째 인자로 지정 혹은 나중에 별도로 subscribe를 호출해서 지정
지난 시간 사용했던 consumer.py에서는

Topic인 'topic_test'를 첫번째 인자로 지정했지만 이번의 실습에서는 KafkaConsumer를 별도로 만들고 subscribe 메서드를 호출해 토픽과 연동하는 형태로 진행하겠습니다.
| 파라미터 | 의미 | 기본 값 |
| bootstrap_servers | 메시지를 보낼 때 사용할 브로커 리스트 (host:port) | localhost:9092 |
| client_id | Kafka Consumer의 이름 | ‘kafka-python-{version} |
| group_id | Kafka Consumer Group의 이름 | |
| key_deserializer, value_deserializer | 메세지의 키와 값의 deserialize 방법 지정 (함수) | |
| auto_offset_reset | earliest, latest | latest |
| enable_auto_commit | True이면 소비자의 오프셋이 백그라운드에서 주기적으로 커밋 False이면 명시적으로 커밋을 해주어야함. 오프셋은 별도로 리셋 가능하며 Client Tool은 물론 Conduktor Web UI에서도 가능 |
True |
group_id는 Kafka Consumer Group을 구별하기 위한 수단으로 쓰입니다. Group이니까 Consumer가 하나 뿐일 때는 Group_id를 쓰지 않아도 되지 않을까 생각하기 쉽지만 Consumer의 숫자와 상관없이 무조건 Group_ID는 세팅해야하며 같은 Group_id에 소속된 Consumer들끼리는 Kafka가 Partition을 나눠주게 됩니다. 그리고 Group을 구성했던 Consumer가 사라지거나 추가되면 Partition을 리밸런싱합니다. 그래서 group_id를 잘못 사용하면 엄청난 문제가 발생하게됩니다. 실제로 현업에서 발생하는 문제이므로 주의를 기울여야 합니다.
auto_offset_reset의 디폴트는 latest입니다. latest인 경우는 새로 들어온 데이터만 읽기 때문에 Consumer를 실행했는데 아무 것도 읽어오지 않았다면 잘못된 것이 아니라 해당 Topic에 지금 데이터가 들어오고 있지 않았기 때문입니다.
The auto_offset_reset parameter in KafkaConsumer determines what the consumer should do when there is no initial offset in Kafka or if the current offset does not exist any more on the server (for example, because that data has been deleted).
- earliest: If auto_offset_reset is set to earliest, the consumer will start reading from the beginning of the topic when there is no initial offset in Kafka or if the current offset does not exist any more on the server.
- latest: If auto_offset_reset is set to latest, the consumer will start reading from the end of the topic, meaning it will only read new messages that arrive after the consumer has started, when there is no initial offset in Kafka or if the current offset does not exist any more on the server.
enable_auto_commit의 True와 False는 각자 장단점이 있습니다. 데이터의 유실이 조금 있어도 크게 중요하지 않다면 True도 가능하며 데이터 유실이 없어야 하고 중복된 데이터라도 다시 꼭 한번 처리해야한다면(at leat once) False를 권장합니다.
Consumer가 다수의 Partitions들로부터 어떻게 읽나?
Consumer의 수보다 Partition의 수가 많다면 Partition을 Consumer들에게 나눠줍니다. 각 Consumer가 하나 혹은 그 이상의 Partition을 담당하겠죠? 각 Partitino들로부터 데이터를 어떻게 읽냐면 기본적으로는 Round Robin으로 읽게 됩니다.
Consumer가 하나이고 다수의 Partitions들로 구성된 Topic으로부터 읽어야한다면?
○ Consumer는 각 Partition들로부터 라운드 로빈 형태로 하나씩 읽게 됨
○ 이 경우 병렬성이 떨어지고 데이터 생산 속도에 따라 Backpressure가 심해질 수 있음
○ 이를 해결하기 위한 것이 뒤에 이야기할 Consumer Group
한 프로세스에서 다수의 Topic을 읽는 것 가능
○ Topic 수만큼 KafkaConsumer 인스턴스 생성하고 별도의 Group ID와 Client ID를 지정해야함
Consumer Group이란?
1) 데이터 소비 병렬성을 확보합니다.
2) Consumer의 삭제와 변경 등의 상황변동을 리밸런싱으로 대처해 어느 정도의 Fault tolerance를 갖추도록 하는데 의미가 있습니다.
Consumer가 Topic을 읽기 시작하면 해당 Topic내 일부 Partition들이 자동으로 할당됨
Consumer의 수보다 Partition의 수가 더 많은 경우, Partition은 라운드 로빈 방식으로 Consumer들에게 할당됨 (한 Partition은 한 Consumer에게만 할당됨)
○ 이를 통해 데이터 소비 병렬성을 늘리고 Backpressure 경감
○ 그리고 Consumer가 일부 중단되더라도 계속해서 데이터 처리 가능
Consumer Group Rebalancing
○ 기존 Consumer가 무슨 이유로 사라지거나 새로운 Consumer가 Group에 참여하는 경우 Partition들이 다시 지정이 되어야함. 이를 Consumer Group Rebalancing이라고 부르면 이는 Kafka에서 알아서 수행해줌
○ 이렇게 Partition이 기존의 Consumer가 아닌 새로운 Consumer에게 지정되면 Partition마다 Consumer가 어디까지 처리되었는지 Offset이 기록되기 때문에 이를 Consumer가 참고해 그 곳부터 읽게 됩니다.
○ 이 때 auto_commit 이 중요해지는데 False로 매뉴얼하게 지정하는 것이 조금 더 정확합니다. 일반적으로 auto_commit이 True라면 주기적으로 commit이 실행되는데 마지막으로 auto_commit하고 사고가 터지고 그 사이 데이터가 처리되게 되면 기록이 남지 않게됩니다. 데이터가 중복처리될 수 있게 되고 데이터 유실이 Producer에서 생기는 등의 문제가 생길 수 있습니다.
Consumer 예제 프로그램 (1)
Offset Auto Commit이 True인 경우
autocommit_consumer.py
import json
from kafka.consumer import KafkaConsumer
def key_deserializer(key):
return key.decode('utf-8')
def value_deserializer(value):
return json.loads(value.decode('utf-8'))
def main():
topic_name = "fake_people"
bootstrap_servers = ["localhost:9092"]
consumer_group_id = "fake_people_group"
consumer = KafkaConsumer(
bootstrap_servers=bootstrap_servers,
group_id=consumer_group_id,
key_deserializer=key_deserializer,
value_deserializer=value_deserializer,
auto_offset_reset='earliest',
enable_auto_commit=True)
consumer.subscribe([topic_name])
for record in consumer:
print(f"""
Consumed person {record.value} with key '{record.key}'
from partition {record.partition} at offset {record.offset}
""")
if __name__ == '__main__':
main()
auto_offset_reset이 earliest여도 늘 반드시 Topic의 맨 앞의 기록부터 읽어오는 것은 아닙니다. 어디까지 읽었는지 기록이 있고 알 수 있다면 그곳부터 읽어오게 할 수도 있습니다.
그런데 latest는 그 기록을 무시하고 Consumer가 실행된 다음에 생긴 레코드들만 읽어옵니다.
그래서 간혹 earliest로 세팅하고 Topic에 데이터가 있는데도 Consumer가 아무 것도 읽어오지 않는 경우가 있는데 바로 해당 Group_id로 앞서 실행한 기록이 있는 경우 그 뒤부터 읽어올텐데 그 기록 이후에는 새로 생긴 데이터가 없어 대기하고 있기 때문입니다.
Consumer 예제 프로그램 (2)
Offset Auto Commit이 False인 경우
manualcommit_consumer.py
import json
from kafka import TopicPartition, OffsetAndMetadata
from kafka.consumer import KafkaConsumer
def key_deserializer(key):
return key.decode('utf-8')
def value_deserializer(value):
return json.loads(value.decode('utf-8'))
def main():
topic_name = "fake_people"
bootstrap_servers = ["localhost:9092"]
consumer_group_id = "manual_fake_people_group"
consumer = KafkaConsumer(
bootstrap_servers=bootstrap_servers,
group_id=consumer_group_id,
key_deserializer=key_deserializer,
value_deserializer=value_deserializer,
auto_offset_reset='earliest',
enable_auto_commit=False)
consumer.subscribe([topic_name])
for record in consumer:
print(f"""
Consumed person {record.value} with key '{record.key}'
from partition {record.partition} at offset {record.offset}
""")
topic_partition = TopicPartition(record.topic, record.partition)
offset = OffsetAndMetadata(record.offset + 1, record.timestamp)
consumer.commit({
topic_partition: offset
})
if __name__ == '__main__':
main()
레코드마다 commit을 하므로 시간은 조금 더 걸리지만 데이터의 정합성은 더 보장됩니다.
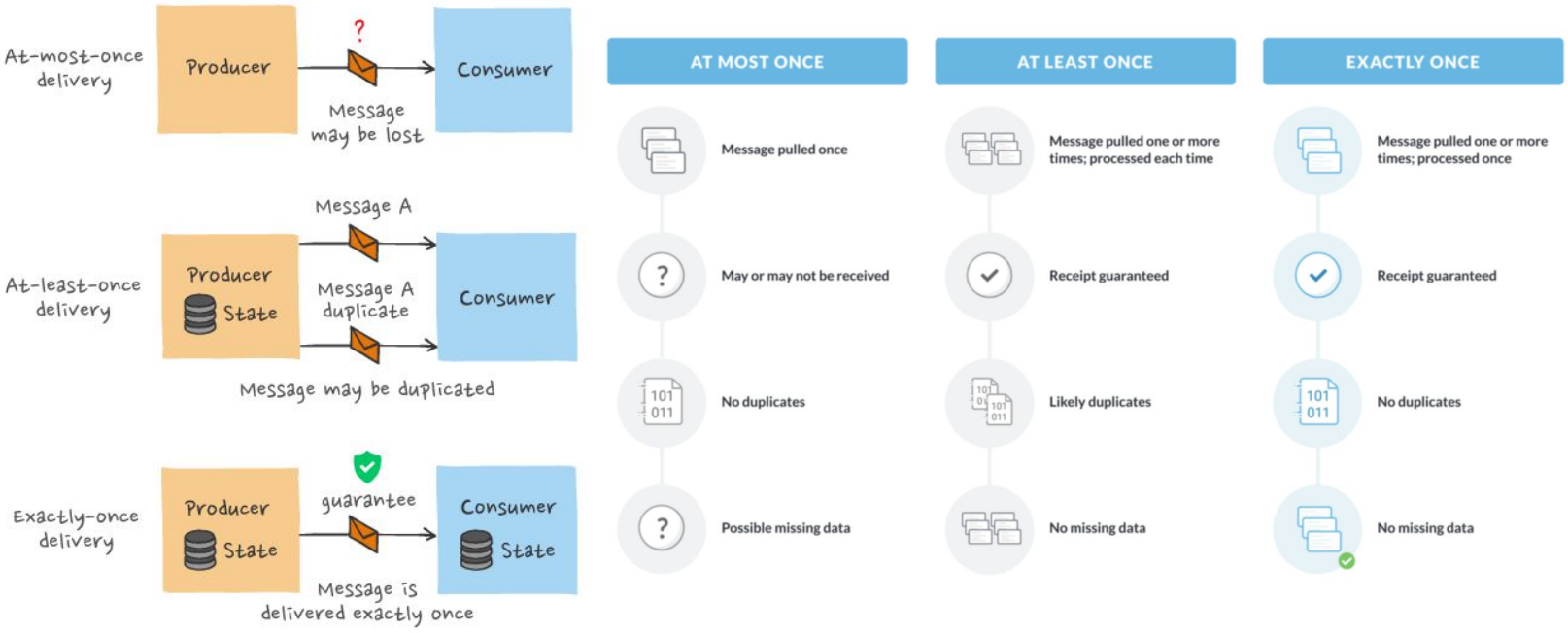
Message Processing Guarantee 방식 (1)
메시지 송수신과 관련해 내가 보낸 메시지가 정말 수신되었는지 확인하는게 중요합니다.
실시간 메시지 처리 및 전송 관점에서 시스템의 보장 방식에는 크게 3가지가 존재
| 방식 | 설명 |
| Exactly Once | Exactly Once('정확히 한 번')는 각 Message가 Consumer에게 정확히 한 번만 전달된다는 것을 보장. 이상적이지만 네트워크 문제, 장애 또는 재시도 가능성으로 아주 어려운 문제. 1> Producer 단에서는 enable_idempotence를 True로 설정 2> Producer에서 메세지를 쓸 때와 Consumer에서 읽을 때 Transaction API를 사용 |
| At Least Once | At Least Once ('적어도 한 번 이상')는 모든 메시지가 Consumer에게 적어도 한 번 이상 전달되도록 보장하지만, 메시지 중복 가능성 존재. 이 경우 Consumer는 중복 메시지를 처리하기 위해 중복 제거 메커니즘을 구현해야함 (멱등성). 이는 보통 Consumer가 직접 오프셋을 커밋을 할때 발생함. |
| At Most Once | At Most Once ('최대 한 번만')는 메시지 손실 가능성에 중점을 둠. 이는 메시지가 손실될 수는 있지만 중복이 없음을 의미. 가장 흔한 메시지 전송 (디폴트) |
Message Processing Guarantee 방식 (2)
Conduktor Web UI에서 Consumer Groups 확인

Consumer/Producer 패턴
많은 경우 Consumer는 한 Topic의 메세지를 소비해서 새로운 Topic을 만들기도함
즉 Consumer이면서 Producer로 동작하는 것이 아주 흔한 패턴임
데이터 Transformation, Filtering, Enrichment
○ 동일한 프로세스 내에서 Kafka Consumer를 사용하여 한 Topic에서 메시지를 읽고 필요한 데이터 변환 또는 Enrichment을 수행한 다음, Producer를 사용하여 수정된 데이터를 다른 Topic으로 푸시 가능
○ Udemy 케이스에서 이미 봤음
Consumer 데모
앞서 코드들을 실제로 실행해보자
위에서 본 autocommit_consumer.py와 manualcommit_consumer.py를 루트 디렉토리에 배치합니다.
먼저 autocommit_consumer.py 실행
PS D:\Dev_KDT\kafka\kafka-stack-docker-compose> python autocommit_consumer.py
(생략..)
Consumed person {'id': 'cb5e289d-6640-4bb9-ac68-7b991abc147d', 'name': 'Kristen Johnson', 'title': 'Musician'} with key 'musician'
from partition 2 at offset 27
그런데 끝나지 않고 대기 상태입니다. 이는 Producer 쪽에서 데이터가 또 만들어져 ingest되면 읽어오기 위해 대기하는 중이기 때문입니다. Kafka Consumer는 기본적으로 이와 같이 동작합니다.
partition과 offset이 보입니다. 간단한 실습이기 때문에 깔끔하게 offset이 증가하고 partition이 나눠졌지만 현업에서는 여러 상황에 따라 이와 같이 아무 문제 없이 완료되지는 않습니다.
Ctrl + C로 종료하고
manualcommit_consumer.py를 실행합니다.
PS D:\Dev_KDT\kafka\kafka-stack-docker-compose> python .\manualcommit_consumer.py
(생략..)
Consumed person {'id': 'eadb41f7-4784-42f0-b358-c6ac75d4980f', 'name': 'Lauren Taylor', 'title': 'It Trainer'} with key 'it-trainer'
from partition 0 at offset 23
겉으로는 별 차이가 없습니다.

Web UI에서 확인해보면
fake_people_group과 manual_fake_people_group이 있습니다.
fake_people_group이 Empty인 이유는 enable_auto_commit이 True였고 실행을 중단했기 때문에 Members(=Consumer)도 0이고 State도 Empty입니다.
manual_fake_people_group은 방금 실행을 해뒀고 아직 돌아가는 중이기 때문에 Members도 1이고 State도 Stable입니다.
둘 모두 동일한 Topic인 fake_people을 읽고 있습니다. (하나의 토픽에 대해 다수의 Consumer가 있을 수 있습니다.)
State 종류들 (https://stackoverflow.com/questions/57253964/kafka-consumergroupstate-explaination)
- Empty: The group exists but no one is in it
- Stable: The rebalancing already took place and consumers are happily consuming.
- PreparingRebalance: Something has changed, and it requires the reassignment of partitions, so Kafka is the middle of rebalancing.
- CompletingRebalance: Kafka is still rebalancing the group. Why there are 2 states for that? More on that in a minute.
- Dead: The group is going to be removed from this Kafka node soon. It might be due to the inactivity, or the group is being migrated to different group coordinator.

manual_fake_people_group을 클릭해 들어가보시면 backpressure가 커서 lag이 있는지, Partition의 수가 얼마나 되는지를 확인할 수 있습니다.
Topic별로 파티션 번호가 있고 마지막 Offset인 END OFFSET과 지금 어디까지 읽었는지인 COMMIT을 볼 수 있습니다. 현재는 모든 Offset을 읽었기 때문에 END OFFSET과 COMMIT의 수가 같은 상황입니다.
Confulent나 Conduktor Web UI 뿐만 아니라 클라이언트 툴로도 볼 수 있습니다.
'Kafka와 Spark Streaming' 카테고리의 다른 글
| 숙제 (0) | 2024.01.25 |
|---|---|
| ksqlDB 사용해보기 (0) | 2024.01.25 |
| Topic 파라미터 설정 (0) | 2024.01.25 |
| Kafka CLI Tools (0) | 2024.01.25 |
| Kafka Python 프로그래밍 기본과 숙제 (0) | 2024.01.24 |