4. Kafka 기본 프로그래밍
Kafka로 데이터를 생성하고 소비하는 코드를 작성해보자
Contents
1. Client tool 사용
2. Topic 파라미터 설정
3. Consumer 옵션 살펴보기
4. ksqlDB 사용해보기
5. 숙제
Topic 파라미터 설정
Topic과 관계된 파라미터들을 KafkaProducer를 통해 설정해보자
Topic 생성시 다수의 Partition이나 Replica를 주려면
Topic을 별도로 생성하지 않고 바로 메시지를 보낼 때, 만일 없는 Topic의 이름을 사용한다면 Kafka가 Scale이 안되고 Partition하나에 Replica하나라는 우리가 바라지 않는 형태로 Topic을 만들게 됩니다.
그래서 이를 막기 위해 Topic을 미리 만들고 우리가 원하는 설정을 하고 그 다음 메시지를 ingest하는 것이 훨씬 바람직합니다. 이를 위해서는
먼저 KafkaAdminClient 오브젝트를 생성하고 create_topics 함수로 Topic을 추가
첫 번째, kafka-python 모듈을 설치할 때 제공되는 KafkaAdminClient 클래스의 객체를 생성하고 이를 통해 create_topics 메서드로 Topic을 만듭니다. KafkaAdminClient는 bootstrap_servers를 알아야 하므로 하나 혹은 다수의 broker 리스트를 지정해야 합니다.
참고) Kafka CLI에서의 --bootstrap-server 옵션과 KafkaAdminClient 객체 생성에서 사용되는 bootstrap_servers는 같은 역할을 하는가?
Yes, the reason is the same.
The --bootstrap-server option in Kafka CLI and the bootstrap_servers parameter in KafkaAdminClient both serve to specify the address of the Kafka server(s) that the client should connect to.
In a Kafka cluster, you can have multiple servers (also known as brokers), and the client only needs to know the address of one of these brokers to connect to the entire cluster. This is because once the client connects to one broker, it will automatically fetch information about the other brokers in the cluster.
So, when you provide the bootstrap_servers parameter in KafkaAdminClient or the --bootstrap-server option in Kafka CLI, you're telling the client where it can find at least one broker in the cluster to connect to.
create_topics의 인자로는 NewTopic 클래스의 오브젝트를 지정
두 번째, 그렇게 지정한 브로커들과 연결을 한 뒤에 NewTopic 타입으로 오브젝트를 만들고 이 오브젝트를 create_topics의 인자로 줍니다.
create_topics 로 복수형인데 인자 역시 리스트인데 다수의 topic을 리스트로 집어 넣고 생성해도 됩니다.
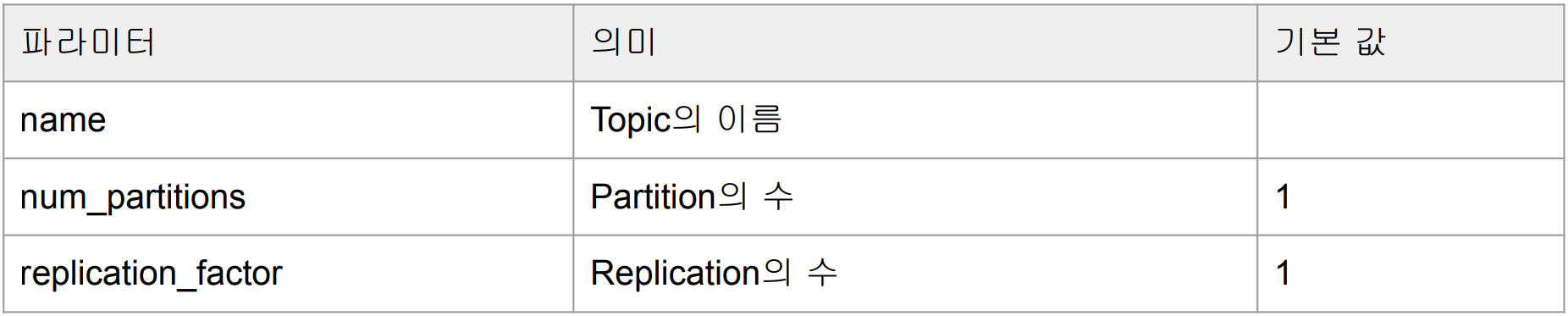
NewTopic은 중요한 인자가 있는데
Topic의 이름인 name, 파티션의 수인 num_partitions, 복제분의 수인 replication_factor입니다.
partitions과 replica의 수는 디폴트로 1입니다. 1은 복제분도 없는 원본만 있다는 의미입니다. 보통은 파티션이 다수이고 복제분이 3으로 원본이 1개, 복제분 2개가 일반적입니다. Consumer의 수와 데이터의 크기가 많고 클수록 파티션의 수가 많은 것이 좋습니다. replication_factor가 클수록 좋습니다.
client = KafkaAdminClient(bootstrap_servers=bootstrap_servers)
topic = NewTopic(
name=name,
num_partitions=partitions,
replication_factor=replica)
client.create_topics([topic])
한 브로커가 다수의 파티션을 처리할 수 있습니다. 지금 우리가 설치한 Kafka는 브로커가 하나밖에 없지만 파티션을 여러 개 가질 수 있습니다. (물론 브로커 하나만으로는 Bandwidth의 이슈가 있을 수 있지만요)
NewTopic 클래스
KafkaProducer 파라미터
| 파라미터 | 의미 | 기본 값 |
| bootstrap | 메세지를 보낼 때 사용할 브로커 리스트 (host:port) | localhost:9092 |
| client_id | Kafka Producer의 이름 | ‘kafka-python-{version} |
| key_serializer, value_serializer | 메세지의 키와 값의 serialize 방법 지정 (함수) | (그냥 그대로 문자열로 넘어감) |
| enable_idempotence | 중복 메세지 전송을 막을 것인지? | False (안 막음) |
| acks: 0, 1, ‘all’ | consistency level. 0: 바로 리턴. 1: 리더(Leader)에 쓰일 때까지는 대기. (Eventual Consistency) (권장) ‘all’: 모든 partition leader/follower에 적용까지 대기 (Strong Consistency) |
0 |
| retries delivery.timeout.ms |
메세지 실패시 재시도 회수 메세지 전송 최대 시간 |
2147483647 120000(120초, 2분) |
| linger_ms, batch_size | 다수의 메세지를 동시에 보내기 위함 (배치 전송) ● 메세지 송신전 대기 시간 ● 메세지 송신전 데이터 크기 |
0 16384 |
| max_in_flight_request_per_connection | Broker에게 응답을 안 기다리고 보낼 수 있는 메세지 중요할 수록 적게, 신속해야할 수록 크게 |
5 (5개 까지는 메시지 패킷을 보내고 응답이 오지 않아도 문제가 없지만 5개를 넘는 순간부터는 응답이 오기를 기다리겠다.) |
KafkaProducer는 실제로 Topic 메시지를 ingest하는 역할을 하는 오브젝트입니다.
참고) acks와 Consistency의 차이점
Strong or Eventual Consistency is about Partition and acks is about replica sync?
Yes, you're on the right track.
In distributed systems, Strong Consistency and Eventual Consistency are concepts that primarily deal with how updates propagate through the system, especially in the presence of partitions (network splits).
- Strong Consistency means that a write operation by any node is instantly seen by all other nodes. No node will ever see an old value after a new value has been written. This is hard to achieve in distributed systems, especially in the presence of network partitions.
- Eventual Consistency means that updates propagate through the system and all nodes eventually converge to the same value, but there might be periods of time where some nodes see old values after a new value has been written. This is often a more practical model for distributed systems, especially those that need to prioritize availability over consistency (according to the CAP theorem).
On the other hand, the acks setting in Kafka is about data durability within a Kafka cluster. It determines how many partition replicas must receive the record before the write is considered successful. This is a trade-off between performance and data durability, not consistency in the traditional sense.
- acks=all ensures that a message is written to all in-sync replicas in the Kafka cluster before the write is considered successful. This provides strong durability guarantees.
- acks=1 means that the message is written to the leader replica and the write is considered successful as soon as the leader has acknowledged the write, without waiting for acknowledgments from follower replicas. This provides weaker durability guarantees.
In Kafka, consumers will always see all messages in the order they were written, regardless of the acks setting. The acks setting affects how many replicas the message is guaranteed to be written to before the write is considered successful, which affects the durability of the message in the face of failures.
Kafka Producer 동작

KafkaProducer.send로 특정 Topic을 지칭해 메시지를 보냅니다.
선택한 Serialize 옵션에 따라 값을 보냅니다.
Topic이 갖고 있는 Partition의 수에 따라 키값의 존재 여부에 따라 어느 Partition에 어느 메시지가 들어갈지 결정합니다.
linger.msbatch.size에 따라 기다릴지 바로 보낼지 결정합니다.
enable.idempotence와 max.in.flight.request.per.connection의 세팅에 따라 멱등성과 응답을 기다릴 메시지에 수에 따라 메시지를 보냅니다.
Kafka Broker는 받은 메시지를 ack 세팅에 따라 0이면 바로 return, 1이면 적어도 Leader 파티션을 갖은 브로커가 해당 파티션의 Segment 파일에 내용이 기록된 다음에 return, all이면 replication_factor에 적힌 수가 3이라면 자기 자신에게 쓰고 다른 2개에 넘겨 그곳에 쓰인게 확인이 된 후에 return합니다. 즉, ack는 Consistency Level을 결정합니다.
KafkaProducer로 토픽 만들기 (1)
랜덤하게 사람 정보를 만들어서 저Kafka Topic에 저장하는 Kafka Producer를 구현해보자
○ Faker라는 모듈 사용: pip3 install faker
○ pydantic의 BaseModel을 사용하여 메세지 클래스를 구현 (Person)
■ pip3 install pydantic
○ 이번에는 Topic을 먼저 만들고 진행

쭉 풀어 얘기하자면
랜덤한 사람 정보를 위해 faker 모듈을 로컬에 설치할 겁니다. KafkaProducer는 Kafka Cluster안에서 돌 필요가 없으므로 로컬 PC 터미널에서 faker를 pip install합니다.
이번에는 메시지 자체를 파이썬 클래스로 만들어 볼겁니다. 파이썬 클래스가 메시지의 value가 되는 형태로 만들텐데 Person이라는 클래스를 만들어 내용을 faker 모듈로 채우고 이를 하나의 메시지로 만들겠습니다. 이 때 pydatic 모듈을 이용할텐데 모듈에 대한 설명은 이후에 드리겠습니다.
앞에서 우리가 보았던 간단한 Producer 코드는 Topic을 만들지 않고 on the fly(별 다른 사전 준비 없이 필요에 따라 바로 실행해보는 것)로 만들었는데 이번에는 Topic을 먼저 만들고 진행하겠습니다.
client = KafkaAdminClient(bootstrap_servers=bootstrap_servers)
topic = NewTopic(
name=name,
num_partitions=partitions,
replication_factor=replica)
client.create_topics([topic])
Topic을 만드는 방식: 위의 코드와 같이 KafkaAdminClient를 먼저 만들고, NewTopic으로 Topic을 만들고, KafkaAdminClient의 create_topics함수에 지정해 다수의 Partition과 다수의 Replica를 갖는 Topic을 만들겠습니다. 그리고 거기에 메시지를 보내는 형태의 실습이 되겠습니다.
class Person(BaseModel):
id: str
name: str
title: strPerson이라는 클래스는 위와 같은 형태로 메시지의 value가 될테고 Key는 이 사람의 직업으로 세팅하겠습니다.
KafkaProducer로 토픽 만들기 (2)
코드 살펴보기: fake_person_producer.py
import uuid
import json
import re
from typing import List
from person import Person
from faker import Faker
from kafka.admin import NewTopic
from kafka.errors import TopicAlreadyExistsError
from kafka import KafkaAdminClient
from kafka.producer import KafkaProducer
def create_topic(bootstrap_servers, name, partitions, replica=1):
client = KafkaAdminClient(bootstrap_servers=bootstrap_servers)
try:
topic = NewTopic(
name=name,
num_partitions=partitions,
replication_factor=replica)
client.create_topics([topic])
except TopicAlreadyExistsError as e:
print(e)
pass
finally:
client.close()
def main():
topic_name = "fake_people"
bootstrap_servers = ["localhost:9092"]
# create a topic first
create_topic(bootstrap_servers, topic_name, 4)
# ingest some random people events
people: List[Person] = []
faker = Faker()
producer = KafkaProducer(
bootstrap_servers=bootstrap_servers,
client_id="Fake_Person_Producer",
)
for _ in range(100):
person = Person(id=str(uuid.uuid4()), name=faker.name(), title=faker.job().title())
people.append(person)
producer.send(
topic=topic_name,
key = re.sub(r'\s+', '-', person.title.lower()).encode('utf-8'),
value=person.json().encode('utf-8'))
producer.flush()
if __name__ == '__main__':
main()# pydantic version 2이상이라면 person.json() 대신 person.model_dump_json() 사용할 경우 경고가 없을겁니다.
"""
Pydantic is a Python library for data parsing and validation.
It uses the type hinting mechanism of the newer versions of Python (version 3.6 onwards)
and validates the types during the runtime. Pydantic defines BaseModel class.
It acts as the base class for creating user defined models.
"""
from pydantic import BaseModel
class Person(BaseModel):
id: str
name: str
title: str
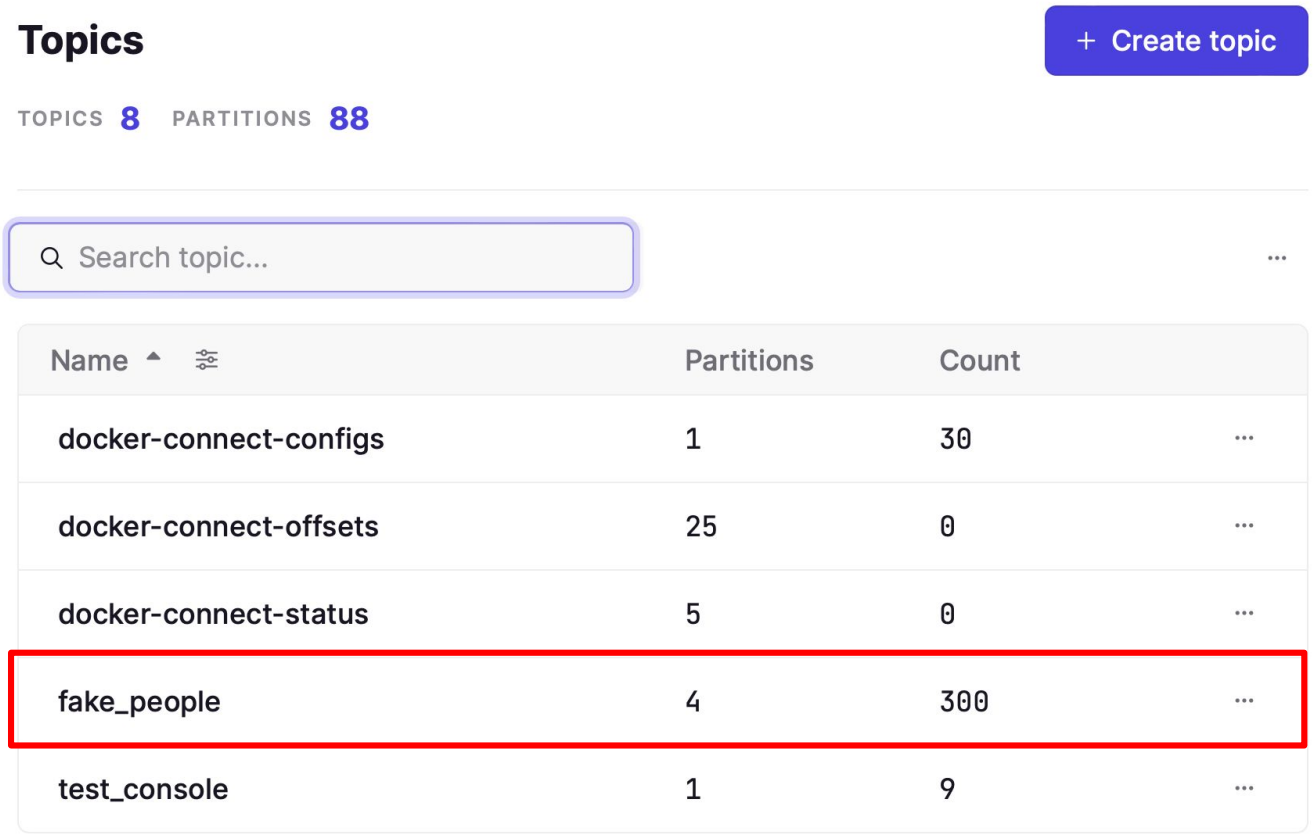
실행한 후 Conduktor Web UI로 토픽 확인
아니면 앞서 설명한 CLI TOOL로 체크 가능
Topic 생성 데모
앞서 내용들을 데모로 실행
pip3 install faker
C:\Users\User>pip3 install faker
Collecting faker
Downloading Faker-22.5.1-py3-none-any.whl.metadata (15 kB)
Requirement already satisfied: python-dateutil>=2.4 in d:\python\anaconda3\lib\site-packages (from faker) (2.8.2)
Requirement already satisfied: six>=1.5 in d:\python\anaconda3\lib\site-packages (from python-dateutil>=2.4->faker) (1.16.0)
Downloading Faker-22.5.1-py3-none-any.whl (1.7 MB)
---------------------------------------- 1.7/1.7 MB 8.5 MB/s eta 0:00:00
Installing collected packages: faker
Successfully installed faker-22.5.1
저는 pydantic은 미리 설치되어있어 faker만 설치했습니다.
fake_person_producer와 person 파이썬 파일 2개를 루트 디렉토리에 배치한 후
PS D:\Dev_KDT\kafka\kafka-stack-docker-compose> python fake_person_producer.py
[Error 36] TopicAlreadyExistsError: Request 'CreateTopicsRequest_v3(create_topic_requests=[(topic='fake_people', num_partitions=4, replication_factor=1, replica_assignment=[], configs=[])], timeout=30000, validate_only=False)' failed with response 'CreateTopicsResponse_v3(throttle_time_ms=0, topic_errors=[(topic='fake_people', error_code=36, error_message="Topic 'fake_people' already exists.")])'.
fake_person_producer.py를 실행합니다.
에러가 났지만 Topic이 이미 만들어진 상황이었기 때문이며 실행은 다 끝났고 큰 문제가 발생한 건 아닙니다.

Web UI에서 Topic을 확인해보니 fake_people이 보이고 for문이 100번 돌며 Count가 100인 것을 볼 수 있습니다.
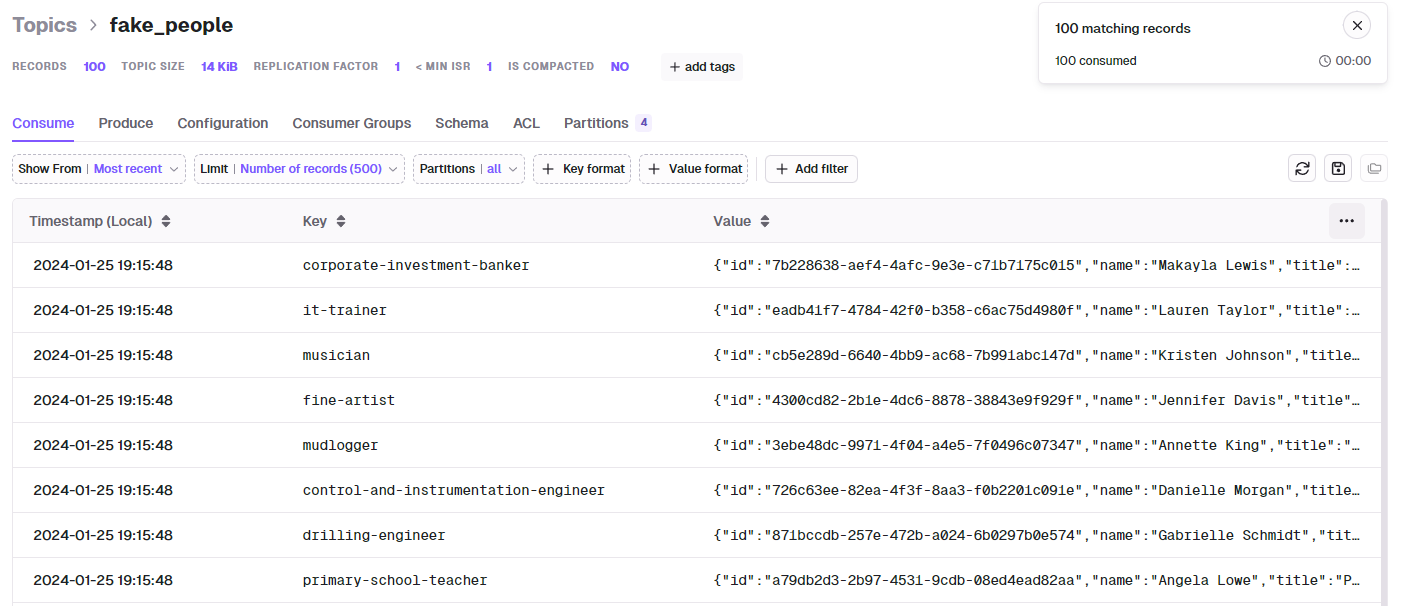
Value에 있는 title이 Key가 되었고 Timestamp가 보이며 Value 랜덤한 uuid를 id로 갖는 등 우리가 의도한대로 작성된 것이 보입니다.
이제 Key가 있고 Partition이 4개가 있기 때문에 레코드들이 Key에 따라 같은 title을 가진 레코드들별로 같은 Partition에 나눠 저장될 것입니다.
이를 이용하면 나중에 유스케이스가 title을 중심으로 작업을 한다면 여러 파티션에서 읽지않고 하나의 파티션에서 읽을 확률이 있겠죠?

WEB UI Topic메뉴에서는 위와 같이 Topic 자체를 삭제하거나 Empty Topic으로 레코드를 없앨 수도 있습니다.
만일 Cousumer가 생기게 된다면 Consumer마다 있는 Offset을 UI에서 리셋할 수 있습니다. 현재는 Consumer가 없지만 Consumer Groups이 실행이 된 상황이라면 Consumer Group ID로 지정한 값이 나올 것입니다. 이는 뒤에서 설명드리고 실습하겠습니다.
'Kafka와 Spark Streaming' 카테고리의 다른 글
| ksqlDB 사용해보기 (0) | 2024.01.25 |
|---|---|
| Consumer 옵션 살펴보기 (0) | 2024.01.25 |
| Kafka CLI Tools (0) | 2024.01.25 |
| Kafka Python 프로그래밍 기본과 숙제 (0) | 2024.01.24 |
| Kafka 설치 (0) | 2024.01.24 |