
터칭 데이터
Spark SQL 실습 1 (JOIN) 본문
Contents
1. Spark SQL 소개
2. Aggregation, JOIN, UDF
3. Spark SQL 실습
4. Hive 메타스토어 사용하기
5. 유닛 테스트
Spark SQL 실습
지금까지 배운 내용들을 실습해보자
실습 문제들
실습 대상 테이블 설명
1. JOIN 실습
2. 매출 사용자 10명 알아내기 (Ranking)
3. 월별 채널별 매출과 방문자 정보 계산하기 (Grouping)
4. 사용자별로 처음 채널과 마지막 채널 알아내기 (Windowing)
실습 사용 테이블 3개 설명 - 사용자 ID, 세션 ID
사용자 ID:
보통 웹서비스에서는 등록된 사용자마다 유일한 ID를 부여 -> 사용자 ID
세션 ID:
사용자가 외부 링크(보통 광고)를 타고 오거나 직접 방문해서 올 경우 세션을 생성
즉 하나의 사용자 ID는 여러 개의 세션 ID를 가질 수 있음
보통 세션의 경우 세션을 만들어낸 소스를 채널이란 이름으로 기록해둠
- 마케팅 관련 기여도 분석을 위함
또한 세션이 생긴 시간도 기록
이 정보를 기반으로 다양한 데이터 분석과 지표 설정이 가능
마케팅 관련
사용자 트래픽 관련
실습 사용 테이블 3개 설명 - 채널과 채널 기여도
사용자 ID 100번: 총 3개의 세션(파란 배경)을 갖는 예제
세션 1: 구글 키워드 광고로 시작한 세션
세션 2: 페이스북 광고를 통해 생긴 세션
세션 3: 네이버 광고를 통해 생긴 세션

뒤의 실습 사용 테이블 3개 설명

1. JOIN 실습
앞서 예제로 배운 두 개의 테이블 대상
Vital
Alert
6개의 조인 수행
INNER
LEFT
RIGHT
FULL
CROSS
SELF
실습
!pip install pyspark==3.3.1 py4j==0.10.9.5
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark SQL #1") \
.getOrCreate()
조인 실습 테이블 2개 로딩
vital = [
{ 'UserID': 100, 'VitalID': 1, 'Date': '2020-01-01', 'Weight': 75 },
{ 'UserID': 100, 'VitalID': 2, 'Date': '2020-01-02', 'Weight': 78 },
{ 'UserID': 101, 'VitalID': 3, 'Date': '2020-01-01', 'Weight': 90 },
{ 'UserID': 101, 'VitalID': 4, 'Date': '2020-01-02', 'Weight': 95 },
]
alert = [
{ 'AlertID': 1, 'VitalID': 4, 'AlertType': 'WeightIncrease', 'Date': '2020-01-01', 'UserID': 101},
{ 'AlertID': 2, 'VitalID': None, 'AlertType': 'MissingVital', 'Date': '2020-01-04', 'UserID': 100},
{ 'AlertID': 3, 'VitalID': None, 'AlertType': 'MissingVital', 'Date': '2020-01-05', 'UserID': 101}
]
rdd_vital = spark.sparkContext.parallelize(vital)
rdd_alert = spark.sparkContext.parallelize(alert)
paralleize를 이용해 rdd로 Spark쪽으로 로딩한 후
df_vital = rdd_vital.toDF()
df_alert = rdd_alert.toDF()
DataFrame으로 만듭니다.
사실은 createDataFrame를 사용해도 됩니다.
df_vital.printSchema()
df_alert.printSchema()
JOIN by DataFrame
# INNER JOIN
join_expr = df_vital.VitalID == df_alert.VitalID
df_vital.join(df_alert, join_expr, "inner").show()
# LEFT JOIN
join_expr = df_vital.VitalID == df_alert.VitalID
df_vital.join(df_alert, join_expr, "left").show()
# RIGHT JOIN
join_expr = df_vital.VitalID == df_alert.VitalID
df_vital.join(df_alert, join_expr, "right").show()
# FULL OUTER JOIN
join_expr = df_vital.VitalID == df_alert.VitalID
df_vital.join(df_alert, join_expr, "full").show()
# CROSS JOIN
df_vital.join(df_alert, None, "cross").show()
# SELF JOIN
join_expr = df_vital.VitalID == df_vital.VitalID
df_vital.join(df_vital, join_expr, "left").show()
JOIN by SQL
df_vital.createOrReplaceTempView("Vital")
df_alert.createOrReplaceTempView("Alert")
# INNER JOIN
df_inner_join = spark.sql("""SELECT * FROM Vital v
JOIN Alert a ON v.vitalID = a.vitalID;""")
df_inner_join.show()
# LEFT JOIN
df_left_join = spark.sql("""SELECT * FROM Vital v
LEFT JOIN Alert a ON v.vitalID = a.vitalID;""")
df_left_join.show()
# RIGHT JOIN
df_right_join = spark.sql("""SELECT * FROM Vital v
RIGHT JOIN Alert a ON v.vitalID = a.vitalID;""")
df_right_join.show()
# OUTER JOIN
df_outer_join = spark.sql("""SELECT * FROM Vital v
FULL JOIN Alert a ON v.vitalID = a.vitalID;""")
df_outer_join.show()
# CROSS JOIN
df_cross_join = spark.sql("""SELECT * FROM Vital v
CROSS JOIN Alert a""")
df_cross_join.show()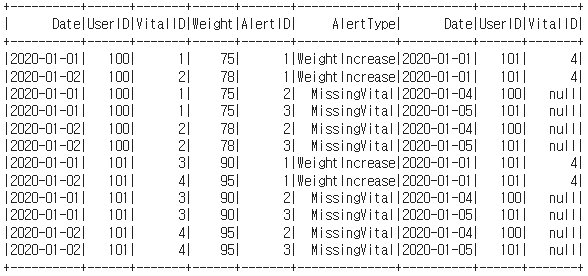
# self JOIN
df_self_join = spark.sql("""SELECT * FROM Vital v1
JOIN Vital v2""")
df_self_join.show()
'하둡과 Spark' 카테고리의 다른 글
| 유닛테스트 (0) | 2024.01.18 |
|---|---|
| Hive - 메타스토어 사용하기 (0) | 2024.01.18 |
| UDF 실습 (0) | 2024.01.18 |
| UDF(User Defined Function) (0) | 2024.01.18 |
| Aggregation - JOIN (0) | 2024.01.18 |



