
터칭 데이터
UDF 실습 본문
Contents
1. Spark SQL 소개
2. Aggregation, JOIN, UDF
3. Spark SQL 실습
4. Hive 메타스토어 사용하기
5. 유닛 테스트
Aggregation, JOIN, UDF
다양한 Aggregation과 JOIN 방식과 UDF에 대해 살펴보자
UDF 실습
앞서 UDF를 실습
하나의 레코드로부터 다수의 레코드 만들어내기
Order 데이터의 items 필드에서 다수의 Order Item 레코드를 만들기

실습
!pip install pyspark==3.3.1 py4j==0.10.9.5
from pyspark.sql import SparkSession
spark = SparkSession \
.builder \
.appName("Python Spark UDF") \
.getOrCreate()
Dataframe/SQL에 UDF 사용해보기 #1 (소문자를 대문자로)
람다 함수
columns = ["Seqno","Name"]
data = [("1", "john jones"),
("2", "tracey smith"),
("3", "amy sanders")]
df = spark.createDataFrame(data=data,schema=columns)
df.show(truncate=False)
import pyspark.sql.functions as F
from pyspark.sql.types import *
upperUDF = F.udf(lambda z:z.upper())
df.withColumn("Curated Name", upperUDF("Name")) \
.show(truncate=False)
파이썬 함수
def upper_udf(s):
return s.upper()
upperUDF = F.udf(upper_udf, StringType())
df.withColumn("Curated Name", upperUDF("Name")) \
.show(truncate=False)
디폴트 타입이 StringType()이므로 굳이 적을 필요는 없지만 실습이므로 적어주었습니다.
withColumn() 대신 select() 사용해보기
df.select("Name", upperUDF("Name").alias("Curated Name")).show()
pandas_udf로 만들어보기
from pyspark.sql.functions import pandas_udf
import pandas as pd
# Define the UDF
@pandas_udf(StringType())
def upper_udf_f(s: pd.Series) -> pd.Series:
return s.str.upper()
# 위에서 정의한 파이썬 upper 함수를 그대로 사용
upperUDF = spark.udf.register("upper_udf", upper_udf_f)
spark.sql("SELECT upper_udf('aBcD')").show()
등록한 upperUDF 레퍼런스를 데이터 프레임에서도 사용해보기
df.select("name", upperUDF("name")).show()
df.createOrReplaceTempView("test")
spark.sql("""
SELECT name, upper_udf(name) `Curated Name` FROM test
""").show()
Dataframe/SQL에 UDF 사용해보기 #2 (두 수의 값을 합하는 함수)
data = [
{"a": 1, "b": 2},
{"a": 5, "b": 5}
]
df = spark.createDataFrame(data)
df.withColumn("c", F.udf(lambda x, y: x + y)("a", "b")).show()
def plus(x, y):
return x + y
plusUDF = spark.udf.register("plus", plus)
spark.sql("SELECT plus(1, 2) sum").show()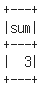
df.withColumn("p", plusUDF("a", "b")).show()
df.createOrReplaceTempView("test")
spark.sql("SELECT a, b, plus(a, b) p FROM test").show()
Dataframe에 UDAF(User Defined Aggregation Function) 사용해보기
from pyspark.sql.functions import pandas_udf
import pandas as pd
# Define the UDF
@pandas_udf(FloatType())
def average_udf_f(v: pd.Series) -> float:
return v.mean()
averageUDF = spark.udf.register('average_udf', average_udf_f)
spark.sql('SELECT average_udf(a) FROM test').show()
df.agg(averageUDF("b").alias("count")).show()
DataFrame에서는 사용할 때 Aggregation 함수이므로 withColumn이 아닌 agg 함수로 사용해야 합니다.
DataFrame에 explode 사용해보기
explode는 하나의 리스트 형태의 레코드로 다수의 레코드들을 만듭니다.
arrayData = [
('James',['Java','Scala'],{'hair':'black','eye':'brown'}),
('Michael',['Spark','Java',None],{'hair':'brown','eye':None}),
('Robert',['CSharp',''],{'hair':'red','eye':''}),
('Washington',None,None),
('Jefferson',['1','2'],{})]
df = spark.createDataFrame(data=arrayData, schema = ['name','knownLanguages','properties'])
df.show()
# knownLanguages 필드를 언어별로 짤라서 새로운 레코드로 생성
from pyspark.sql.functions import explode
df2 = df.select(df.name,explode(df.knownLanguages))
df2.printSchema()
df2.show()
하나의 레코드에서 다수의 레코드를 만들어내는 예제 (Order to 1+ Items)
!wget https://s3-geospatial.s3.us-west-2.amazonaws.com/orders.csv
!head -5 orders.csv
Spark으로 데이터를 로딩해 처리하기
from pyspark.sql.functions import *
from pyspark.sql.types import StructType, StructField, StringType, ArrayType, LongType
order = spark.read.options(delimiter='\t').option("header","true").csv("orders.csv")
다운 받은 order.csv는 일반 csv와는 다르게 탭으로 구분된 파일입니다. delimiter로 '\t'을 주었습니다.
헤더가 있으므로 true를 주었고 path를 주었습니다.
order.show()
order.printSchema()
items 컬럼은 리스트인데 현재 string으로 인식 중입니다. 리스트로 인식시키고 리스트 안의 내용들을 각각의 레코드로 explode때 처럼 분해(break)해보겠습니다.
# 데이터프레임을 이용해서 해보기
struct = ArrayType(
StructType([
StructField("name", StringType()),
StructField("id", StringType()),
StructField("quantity", LongType())
])
)
order.withColumn("item", explode(from_json("items", struct))).show(truncate=False)
order_items = order.withColumn("item", explode(from_json("items", struct))).drop("items")order_items.show(5)
order_items.printSchema()
order_items.createOrReplaceTempView("order_items")spark.sql("""
SELECT order_id, CAST(average_udf(item.quantity) as decimal) avg_count
FROM order_items
GROUP BY 1
ORDER BY 2 DESC""").show(5)
spark.sql("""SELECT item.quantity FROM order_items WHERE order_id = '1816674631892'""").show()
spark.catalog.listTables()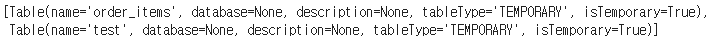
SparkSession에 등록한 UDF 확인하는 법
for f in spark.catalog.listFunctions():
print(f[0])
우리가 만든 UDF외에도 네이티브 함수도 출력하므로 굉장히 많은 함수들이 출려됩니다.
'하둡과 Spark' 카테고리의 다른 글
| Hive - 메타스토어 사용하기 (0) | 2024.01.18 |
|---|---|
| Spark SQL 실습 1 (JOIN) (0) | 2024.01.18 |
| UDF(User Defined Function) (0) | 2024.01.18 |
| Aggregation - JOIN (0) | 2024.01.18 |
| Spark SQL 소개 (0) | 2024.01.18 |



