데모: dbt Models: Input & Output
앞서 내용들을 전체적으로 직접 실행해보자

아까 설치한 learn_dbt 프로젝트로 이동하여 dbt_project.yml 파일을 수정할겁니다.

마지막 두 줄을 삭제합니다. 예제로 만들어져 우리가 사용하지 않기 때문입니다.
삭제 후 저장을 마치고
models 폴더의 example 폴더를 삭제합니다.

대신 src 폴더를 만들고 src 폴더로 이동한 후 3개의 파일을 만듭니다.
src_user_event.sql
WITH src_user_event AS (
SELECT * FROM raw_data.user_event
)
SELECT
user_id,
datestamp,
item_id,
clicked,
purchased,
paidamount
FROM
src_user_event
src_user_variant.sql
WITH src_user_variant AS (
SELECT * FROM raw_data.user_variant
)
SELECT
user_id,
variant_id
FROM
src_user_variant
src_user_metadata.sql
WITH src_user_metadata AS (
SELECT * FROM raw_data.user_metadata
)
SELECT
user_id,
age,
gender,
updated_at
FROM
src_user_metadata

최종 src 폴더의 모습
PS D:\Dev_KDT\dbt\learn_dbt> dbt run
learn_dbt 디렉토리에서
dbt run 명령을 실행하면 3개의 Input이 만들어집니다.
그리고 models 폴더에 dim과 fact 폴더 2개를 만듭니다.
그리고 dim 디렉토리에 아래와 같은 sql 파일 2개를 만들어주세요.
dim_user_variant.sql
WITH src_user_variant AS (
SELECT * FROM {{ ref('src_user_variant') }}
)
SELECT
user_id,
variant_id
FROM
src_user_variant
dim_user_metadata.sql
WITH src_user_metadata AS (
SELECT * FROM {{ ref('src_user_metadata') }}
)
SELECT
user_id,
age,
gender,
updated_at
FROM
src_user_metadata

최종 dim 폴더의 모습
fact 폴더에도 sql 파일 하나를 만들어줍니다.
fact_user_event.sql
{{
config(
materialized = 'incremental',
on_schema_change='fail'
)
}}
WITH src_user_event AS (
SELECT * FROM {{ ref("src_user_event") }}
)
SELECT
user_id,
datestamp,
item_id,
clicked,
purchased,
paidamount
FROM
src_user_event

fact 폴더의 모습

src, dim, fact 3개의 폴더별로 어떤 형태로 테이블의 포맷을 정할지 laern_dbt 폴더의 dbt_project.yml 파일에 정의하겠습니다.
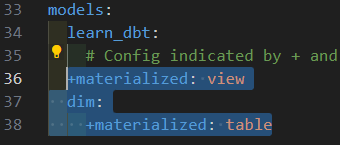
우리가 아까 example을 지웠던 최하단부에 위와 같이 적어줍니다.
learn_dbt 밑에 models에서 만들어지는 데이터들은 전부 view로 만들어지지만 dim 폴더에서 만들어지는 데이터들은 테이블로 만들겠다는 세팅입니다. dim처럼 materialized: table이 아닌 fact는 데이터들이 view로 만들어집니다.
PS D:\Dev_KDT\dbt\learn_dbt> dbt compile
07:33:23 Found 6 models, 0 sources, 0 exposures, 0 metrics, 455 macros, 0 groups, 0 semantic models
dbt compile 명령으로 6개의 모델이 잡히는 것을 볼 수 있습니다.
PS D:\Dev_KDT\dbt\learn_dbt> dbt run
그 다음 dbt run으로 스테이징 테이블로 view 3개가 만들어 졌습니다.
dim 테이블들은 table로 physical table로 만들어지고
fact 테이블은 incremental model임을 확인할 수 있을겁니다.
이제 fact 폴더의 fact_user_event.sql 최하단부에

하이라이트 된 코드를 적어주세요.
(현재 제 VScode에 dbt extension이 설치되어 있지 않아 빨간 줄이 떠 있는데 실행에는 문제가 없습니다.)
PS D:\Dev_KDT\dbt\learn_dbt> dbt run
그리고 다시 dbt run을 실행합니다.
fact 테이블이 incremental update가 되었는지 불분명한 상황이므로 postico와 같은 프로그램의 도움을 받아 원본 테이블인 raw_data.user_event에 새로운 레코드를 적재하고 다시 dbt run을 실행하겠습니다.
그 전에 적당한 Redshift 클라이언트 툴에서 아래를 수행합니다.
SELECT COUNT(1) FROM (각자 스키마).dim_user_metadata;
-- 10000
SELECT COUNT(1) FROM (각자 스키마).dim_user_variant;
-- 10000
SELECT COUNT(1) FROM (각자 스키마).fact_user_variant;
-- 3892760
정말로 COPY가 제대로 되었는지 core table들을 COUNT 해보겠습니다.
각각 100000, 100000, 3892760 개의 레코드가 있습니다.
그리고 아래와 같이 레코드 하나를 추가합니다.
INSERT INTO raw_data.user_event VALUES (100, '2023-06-10', 100, 1, 0, 0);
SELECT * FROM raw_data.user_event WHERE datestamp = '2023-06-10';
이제 터미널에서 dbt run 실행 후 fact_user_event 테이블에 방금 추가한 레코드가 들어갔는지 확인합니다.
PS D:\Dev_KDT\dbt\learn_dbt> dbt run
성공은 하지만 화면만으로는 아직 알 수가 없습니다.
이를 확인할 수 있는 한 가지 방법이 있습니다.
learn_dbt/models/fact 뿐만 아니라

learn_dbt/target/compiled/learn_dbt/models/fact 에도 fact 폴더와 fact_user_event.sql 파일이 존재합니다.

우리가 사용한 jinja template에 값이 실제로 치환되어 들어간 최종 SQL문입니다.
좌측의 {{ ref("src_user_event") }}이 우측에서는 실제 값으로 치환되어 있습니다.
그 외에도 WHERE절 역시 실제 값으로 치환되어 있습니다.
이제 가장 큰 datestamp를 뽑고 그것보다 더 큰 2023-06-10 레코드 하나만 뽑힐 겁니다.
그리고 이 결과가 temporary 테이블에 저장되고 최종적으로 fact 테이블에 insert 됩니다.
방금 우리가 살펴 본 learn_dbt/target/compiled/learn_dbt/models/fact 말고도
learn_dbt/run/compiled/learn_dbt/models/fact에도 fact_user_event.sql이 존재합니다.
이 파일을 보면

incremental update를 위해 tmp131407551524라는 테이블이 하나 생기고 이 테이블의 내용이 최종적으로 fact table에 insert됩니다.
좀 더 자세한 내용은
learn_dbt/run/compiled/learn_dbt/models/dim 의 dim_user_variant.sql에서 살펴볼 수 있습니다.

CTAS로 스테이징 테이블의 내용들을 꺼내 최종적으로 dev라는 데이터베이스의 사용자 스키마에 dim_user~tmp 테이블을 만들고 이후 성공한다면 내부적으로 원본 테이블을 삭제하고 이 테이블을 원본의 이름으로 rename하는 방식으로 전개됩니다.
이제 적당한 postico 같은 적당한 Redshift 클라이언트 툴에서
SELECT * FROM (각자 스키마).fact_user_event WHERE datestamp='2023-06-10'
쿼리를 실행합니다.

정상적으로 Incremental Update가 이루어졌습니다.
마지막으로 하나만 더 데모를 해보겠습니다.
4가지의 Materialization 종류
View
데이터를 자주 사용하지 않는 경우
Table
데이터를 반복해서 자주 사용하는 경우
Incremental (Table Appends)
Fact 테이블
과거 레코드를 수정할 필요가 없는 경우
Ephemeral (CTE)
한 SELECT에서 자주 사용되는 데이터를 모듈화하는데 사용
우리는 바로 이전에 스테이징 테이블을 View로 실습했습니다. 사실 View는 잘 사용되지 않습니다. 이번에는 CTE 방식인 Ephemeral을 사용하겠습니다.

learn_dbt/dbt_project.yml에 하이라이트된 코드를 추가해주세요.
dbt run으로 view를 정말 안 만드는지 메시지를 하나하나 읽어 확인할 수도 있지만
더 직관적이고 편리한 확인을 위해 postico에서 3개의 View를 먼저 삭제하겠습니다.
DROP VIEW (각자 스키마).src_user_event;
DROP VIEW (각자 스키마).src_user_metadata;
DROP VIEW (각자 스키마).src_user_variant
PS D:\Dev_KDT\dbt\learn_dbt> dbt run
모델은 6개를 찾았는데 모델 빌딩은 3개만 이루어집니다.
View를 명시적으로 만들지 않고 CTE로 fact와 dim 테이블을 만드는데 임베딩되었기 때문입니다.
정말로 그런지 learn_dbt/target/compiled/learn_dbt/models/dim 경로에 dim_user_variant.sql를 보겠습니다.

바로 이전 실습에서 src에 사용했던 CTE로 select하던 부분이 하이라이트된 부분으로 임베드된 것을 볼 수 있습니다.
일반적으로 스테이징 테이블은 View나 Table로 만들 필요가 없으며 CTE(Ephemeral)로 사용하는 것이 일반적입니다.
최종적으로 dim_user와 analytics_variant_user_daily 테이블을 만들고 끝내겠습니다.
models/dims 폴더에
dim_user.sql 파일을 만들어
WITH um AS (
SELECT * FROM {{ ref("dim_user_metadata") }}
), uv AS (
SELECT * FROM {{ ref("dim_user_variant") }}
)
SELECT
uv.user_id,
uv.variant_id,
um.age,
um.gender
FROM uv
LEFT JOIN um ON uv.user_id = um.user_id
위와 같이 작성합니다.
models 폴더에 analytics라는 새로운 폴더를 만들고 이 아래에
analytics_variant_user_daily.sql 파일을 만들어
WITH u AS (
SELECT * FROM {{ ref("dim_user") }}
), ue AS (
SELECT * FROM {{ ref("fact_user_event") }}
)
SELECT
variant_id,
ue.user_id,
datestamp,
age,
gender,
COUNT(DISTINCT item_id) num_of_items, -- 총 impression
COUNT(DISTINCT CASE WHEN clicked THEN item_id END) num_of_clicks, -- 총 click
SUM(purchased) num_of_purchases, -- 총 purchase
SUM(paidamount) revenue -- 총 revenue
FROM ue LEFT JOIN u ON ue.user_id = u.user_id
GROUP by 1, 2, 3, 4, 5
위와 같이 작성합니다.
이제 dbt run을 실행합니다.
그 다음 postico와 같은 툴에서 analytics_variant_user_daily 테이블 내용을 보시면 일별로 사용자들의 행동 내역이 요약되어 있을테고 그 사용자에 따른 속성데이터들도 같이 조회될 것입니다.
이를 이용해 A와 B의 퍼포먼스를 비교할 수 있습니다.
'Airflow 고급 기능, dbt, Data Catalog' 카테고리의 다른 글
| DBT Sources (0) | 2024.01.05 |
|---|---|
| DBT Seeds (0) | 2024.01.05 |
| DBT - Outnput (0) | 2024.01.04 |
| DBT - Input (0) | 2024.01.04 |
| DBT - 사용 시나리오 (0) | 2024.01.04 |