
터칭 데이터
DBT - Outnput 본문
Contents
1. ELT의 미래는?
2. Database Normalization
3. dbt 소개
4. dbt 사용 시나리오
5. dbt 설치와 환경 설정
6. dbt Models: Input
7. dbt Models: Output
8. dbt Seeds
9. dbt Sources
10. dbt Snapshots
11. dbt Tests
12. dbt Documentation
13. dbt Expectations
14. 마무리
dbt Models: Output
최종 출력 데이터를 만드는 과정을 살펴보자
Materialization이란?
입력 데이터(테이블)들을 연결해서 새로운 데이터(테이블) 생성하는 것
보통 여기서 추가 transformation이나 데이터 클린업 수행
4가지의 내장 materialization이 제공됨
파일이나 프로젝트 레벨에서 가능
역시 dbt run을 기타 파라미터를 가지고 실행
4가지의 Materialization 종류
View
데이터를 자주 사용하지 않는 경우
Table
데이터를 반복해서 자주 사용하는 경우
Incremental (Table Appends)
Fact 테이블
과거 레코드를 수정할 필요가 없는 경우
Ephemeral (CTE)
한 SELECT에서 자주 사용되는 데이터를 모듈화하는데 사용
데이터 빌딩 프로세스

잠깐 Jinja 템플릿이란?
파이썬이 제공해주는 템플릿 엔진으로 Flask에서 많이 사용
Airflow에서도 사용함
입력 파라미터 기준으로 HTML 페이지(마크업)를 동적으로 생성
조건문, 루프, 필터등을 제공
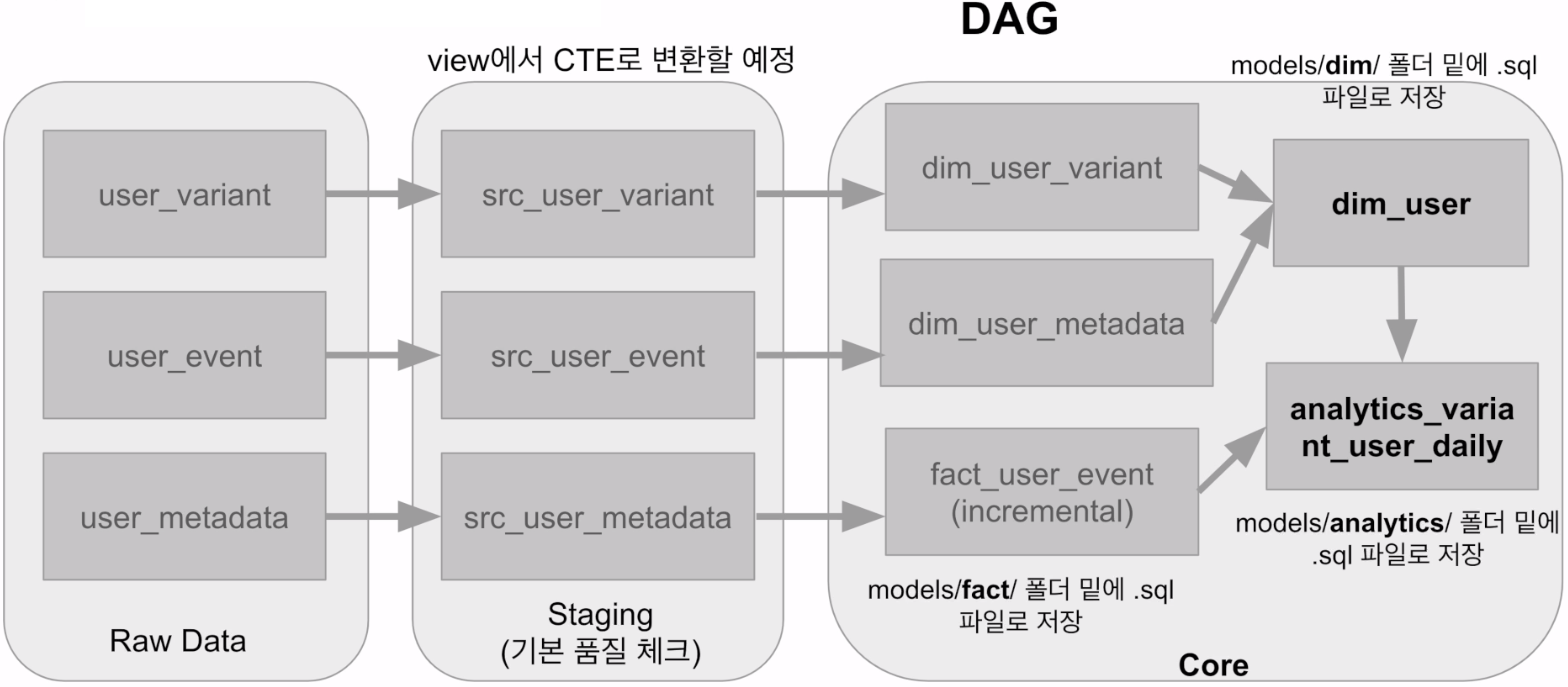
models 밑에 core 테이블들을 위한 폴더 생성
dim 폴더와 fact 폴더 생성
dim 밑에 각각 dim_user_variant.sql과 dim_user_metadata.sql 생성
fact 밑에 fact_user_event.sql 생성
이 모두를 physical table로 생성
models/dim - dim_user_variant.sql
Jinja 템플릿과 ref 태그를 사용해서 dbt 내 다른 테이블들을 액세스

models/dim - dim_user_metadata.sql
설정에 따라 view/table/CTE 등으로 만들어져서 사용됨
materialized라는 키워드로 설정

models/fact - fact_user_event.sql
Incremental Table로 빌드 (materialized = 'incremental')
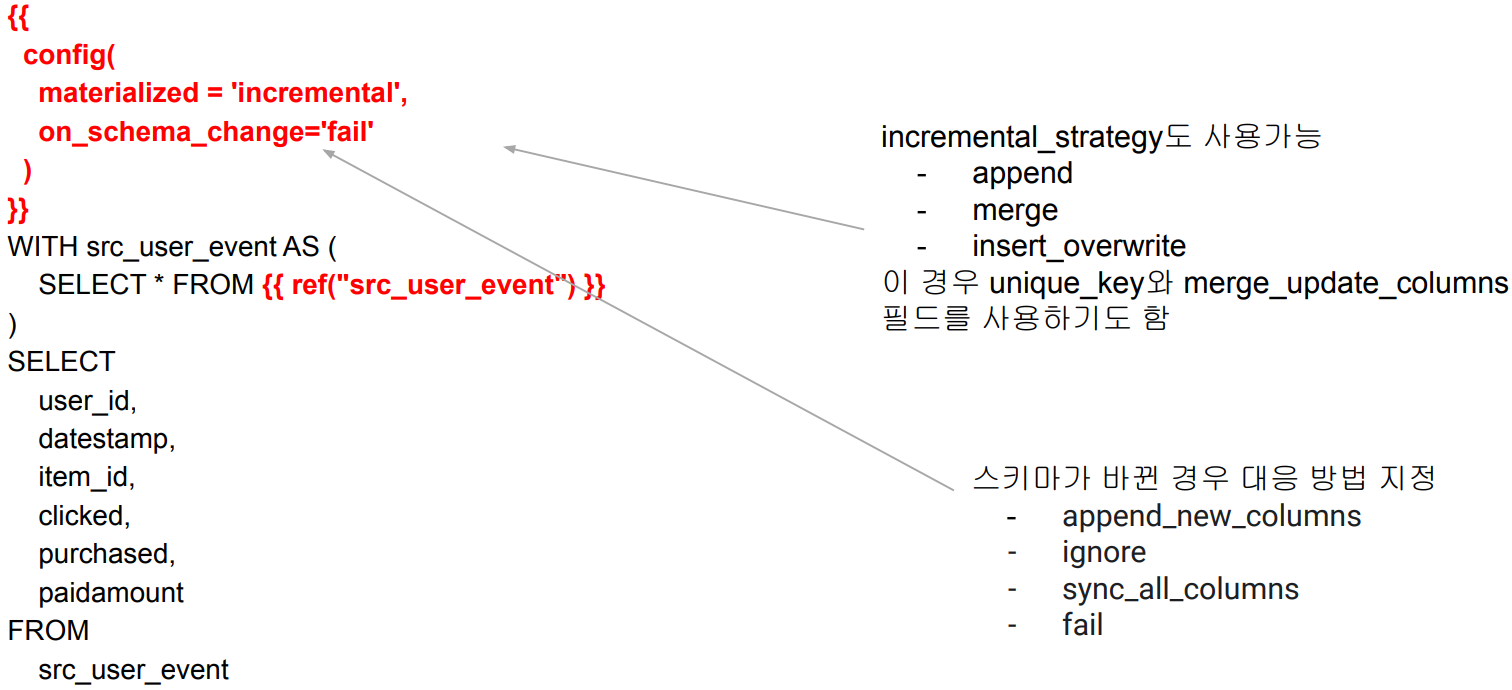
다음으로 model의 materialized format 결정
최종 Core 테이블들은 view가 아닌 table로 빌드
dbt_project.yml을 편집

Model 빌딩: dbt run (dbt compile도 있음)
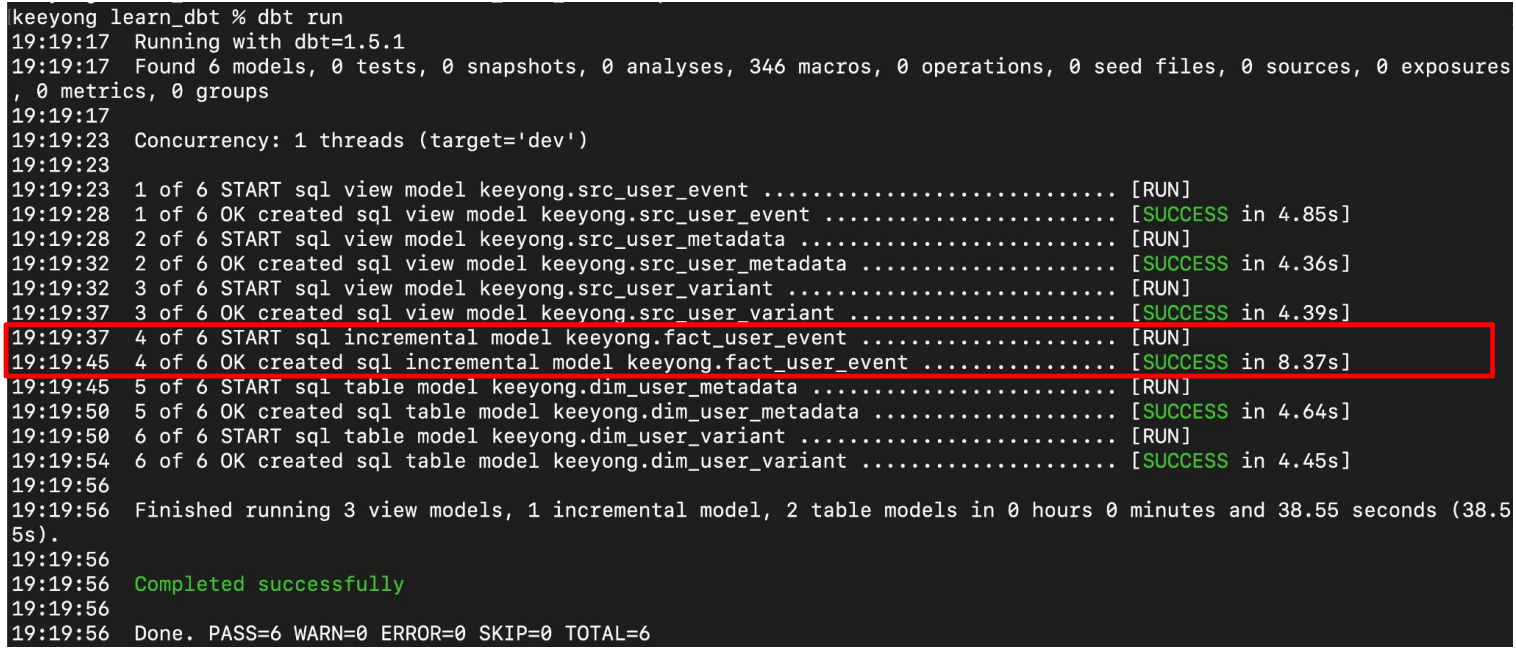
dbt compile vs. dbt run
dbt compile은 SQL 코드까지만 생성하고 실행하지는 않음
dbt run은 생성된 코드를 실제 실행함
Model 빌딩 확인

해당 스키마 밑에 테이블 생성 여부 확인
Core 테이블들은 Table
Staging 테이블들은 View
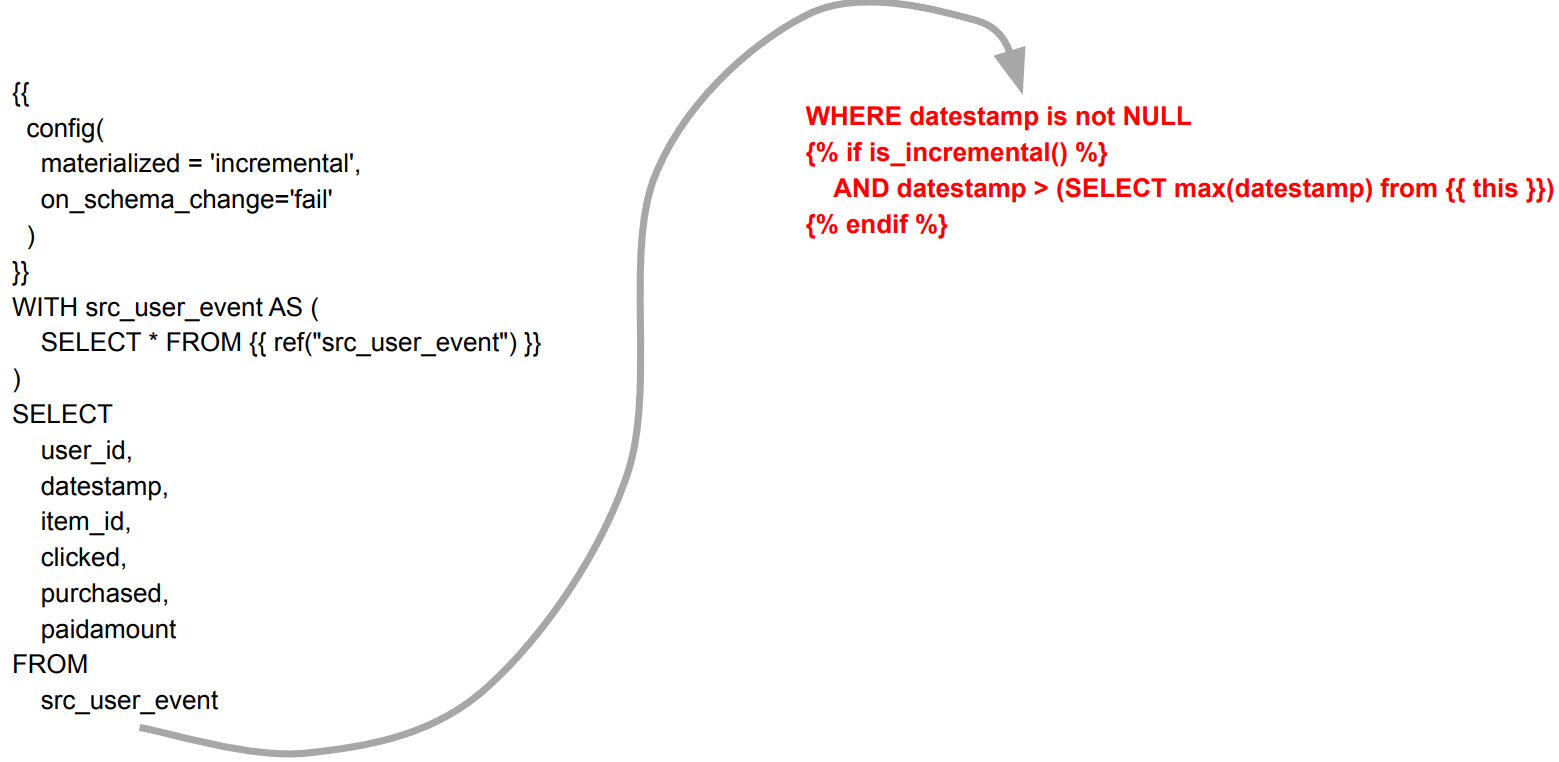
models/fact - fact_user_event.sql
WHERE 조건 붙이기
raw_data.user_event에 새 레코드 추가후 dbt run 수행
적당한 Redshift 클라이언트 툴에서 아래 수행
INSERT INTO raw_data.user_event VALUES (100, '2023-06-10', 100, 1, 0, 0);
다음으로 dbt run을 수행
compiled SQL을 확인해서 정말 Incremental하게 업데이트되었는지 확인
최종적으로 Redshift 클라이언트 툴에서 다시 확인
SELECT * FROM keeyong.fact_user_event WHERE datestamp = '2023-06-10';
Model 빌딩: Compile 결과확인
learn_dbt/target/compiled/learn_dbt/models/fact
fact_user_event.sql의 내용은 아래와 같음
WITH src_user_event AS (
SELECT * FROM "dev"."keeyong"."src_user_event"
)
SELECT
user_id,
datestamp,
item_id,
clicked,
purchased,
paidamount
FROM
src_user_event
WHERE datestamp is not NULL
AND datestamp > (SELECT max(datestamp) from "dev"."keeyong"."fact_user_event")
◆ src 테이블들을 CTE로 변환해보기
❖ src 테이블들을 굳이 빌드할 필요가 있나?
❖ dbt_project.yml 편집
models:
learn_dbt:
# Config indicated by + and applies to all files under models
+materialized: view
dim:
+materialized: table
src:
+materialized: ephemeral
src 테이블들 (View) 삭제
DROP VIEW keeyong.src_user_event;
DROP VIEW keeyong.src_user_metadata;
DROP VIEW keeyong.src_user_variant
dbt run 실행
이제 SRC 테이블들은 CTE 형태로 임베드되어서 빌드됨
Model 빌딩: dbt run (dbt compile도 있음)
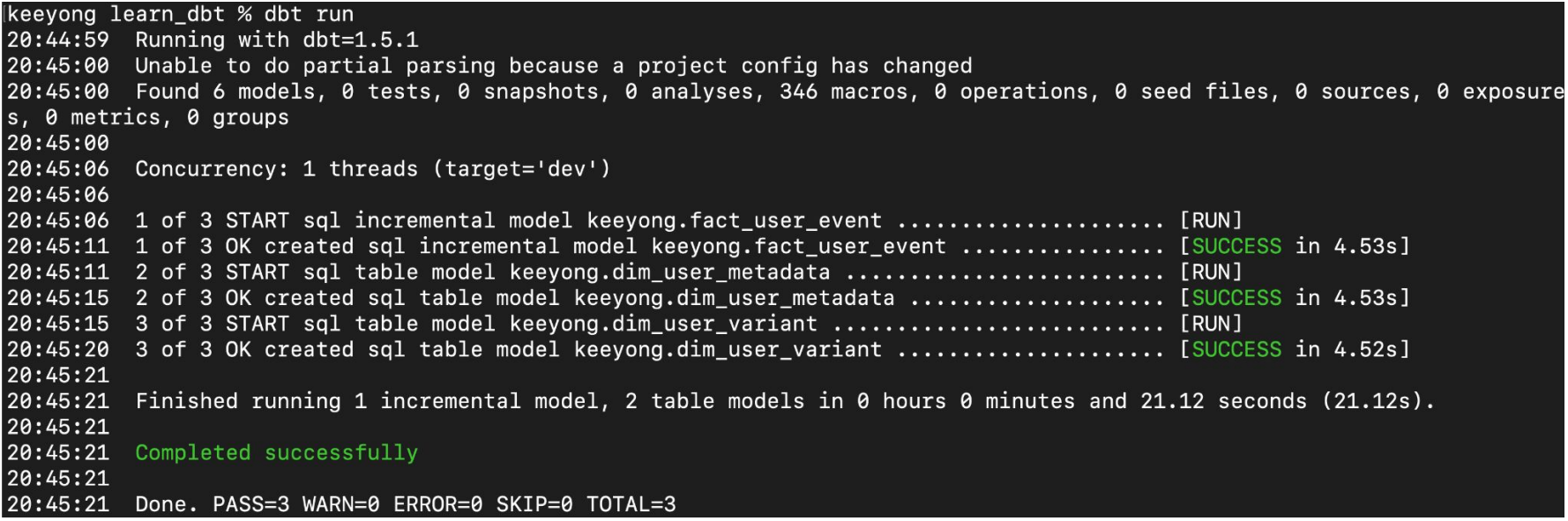
src 테이블 빌드와 관련된 부분들이 빠져있음
데이터 빌딩 프로세스
models/dim - dim_user.sql
dim_user_variant와 dim_user_metadata를 조인

models/analytics - analytics_variant_user_daily.sql
dim_user와 fact_user_event를 조인 - analytics 폴더를 models 밑에 생성

Model 빌딩: dbt run
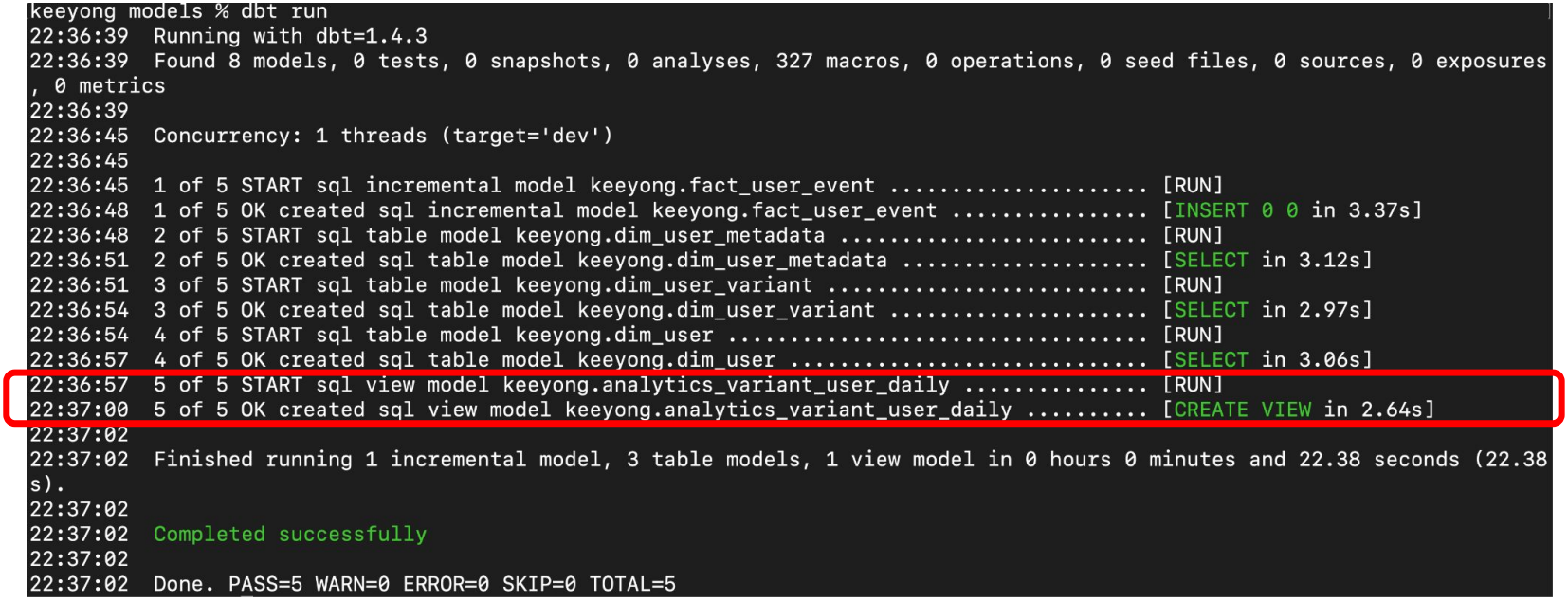
최종 테이블까지 생성
'Airflow 고급 기능, dbt, Data Catalog' 카테고리의 다른 글
| DBT Seeds (0) | 2024.01.05 |
|---|---|
| 데모 Input-Output (0) | 2024.01.04 |
| DBT - Input (0) | 2024.01.04 |
| DBT - 사용 시나리오 (0) | 2024.01.04 |
| DBT - Database Normalization (0) | 2024.01.04 |



