Airflow를 구성하는 컴포넌트와 스케일링 방법과 코드 구조에 대해 알아보자
Airflow - 총 5개의 컴포넌트로 구성
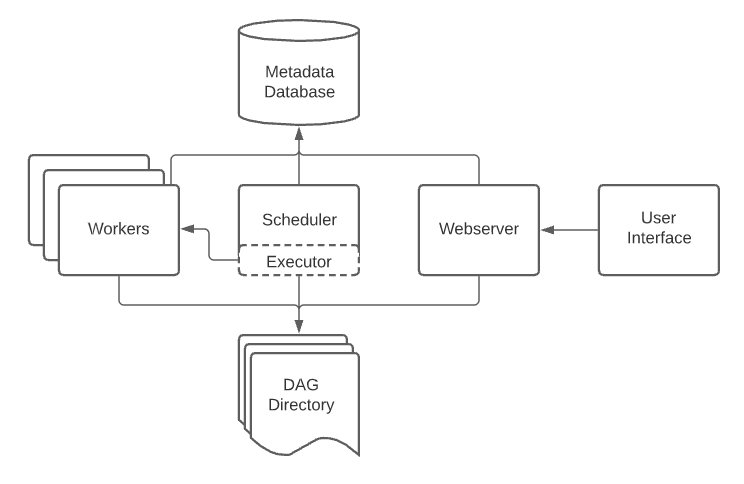
1. 웹 서버 (Web Server)
Python Flask로 구현
스케줄러와 DAG의 현황을 표시
2. 스케줄러 (Scheduler)
데이터 파이프라인을 워커에게 배정
3. 워커 (Worker)
태스크에 해당하는 코드를 실행
4. 메타 데이터 데이터베이스
a. Sqlite가 기본으로 설치되었지만 싱글 코어에 파일 기반이므로 테스트 용도로도 성능이 좋지 않아 MySQL이나 PostgreSQL 등을 따로 설치해 사용
5. 큐 (다수서버 구성인 경우에만 사용됨)
Airflow를 다수의 서버로 구성하는 경우 데이터 파이프라인에 어떤 태스크가 어떤 워커로 실행될 것인지를 큐에 넣어 두어 판단
a. 이 경우 Executor가 달라짐 (Excutor의 자세한 설명은 추후에)
- 스케줄러가 마스터 워커가 일꾼
- Airflow를 스케일링 하는 것은 워커의 수를 늘리는 것
- 웹 서버, 스케줄러, 워커 3개의 컴포넌트가 자신의 상황을 기록하는 곳이 메타 데이터 DB
- 태스크가 다수의 워커로 분산되어 처리되려면 중간의 매개체가 필요하고 이것이 큐
Airflow 구성
스케줄러는 DAG들을 워커들에게 배정하는 역할을 수행
정해진 시간, 의존 관계에 따라 A를 따라 B를 실행, 정확하게는 DAG가 아닌 DAG안의 태스크(Task)를 스케줄링
웹 UI는 스케줄러와 DAG의 실행 상황을 시각화해줌
워커는 실제로 DAG를 실행하는 역할을 수행
스케줄러와 각 DAG의 실행결과는 별도 DB에 저장됨
-기본으로 설치되는 DB는 SQLite
- 실제 프로덕션에서는 MySQL이나 Postgres를 사용해야함
Airflow 구조: 서버 한대

한대의 서버에 Worker, Scheduler, WebServer
Worker는 서버의 CPU 수만큼 동시에 동작
Airflow 스케일링 방법

스케일 업
더 좋은 사양의 서버를 사용, 기술의 발전 속도에 따라 한계가 존재할 수도 있음
스케일 아웃
서버의 수를 늘리는데 늘어난 서버는 워커들이 사용
처음에는 한대의 에어플로우 서버를 사용하다 용량이 부족하다면 Scale Up을 통해 사양을 높이고 Scale Up의 한계에 봉착하면 Scale Out으로 서버를 늘리는 방식을 권장합니다. Scale Out을 할 때는 직접 서버를 늘리지 않고 Airflow를 이용하는 클라우드 서비스를 이용합니다.
Airflow 구조: 다수 서버
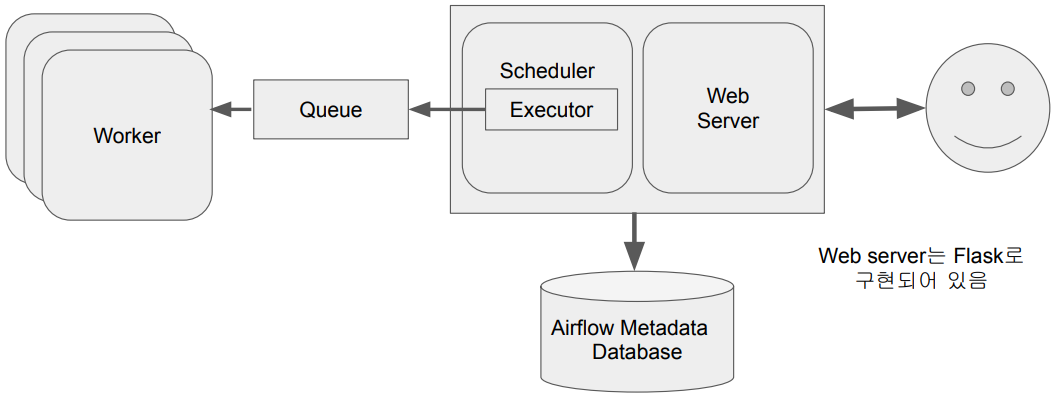
마스터 노드가 메타 데이터 데이터 베이스와 연결이 된 상태에서 다수의 워커들에게 큐를 통해 일을 시킵니다.
Executor :
스케줄러는 워커에게 바로 데이터를 전달하지 않고 Executor를 통해 전달합니다.
아래와 같은 여러 종류의 Exceutor들이 있는데 default는 Sequential Executor지만 제약이 많다.
Sequential Executor
Local Executor
Celery Executor
Kubernetes Executor
CeleryKubernetes Executor
Dask Executor
Airflow 개발의 장단점
장점
데이터 파이프라인을 세밀하게 제어 가능
다양한 데이터 소스와 데이터 웨어하우스를 지원
백필(Backfill)이 쉬움
단점
배우기가 쉽지 않음
상대적으로 개발환경을 구성하기가 쉽지 않음
직접 운영이 쉽지 않음. 클라우드 버전 사용이 선호됨
- GCP provides “Cloud Composer”
- AWS provides “Managed Workflows for Apache Airflow”
- Azure provides “Data Factory Managed Airflow”
DAG란 무엇인가?
Directed Acyclic Graph의 줄임말
양방향이 아닌 일방향이므로 Directed이고 순환하는 Loop가 아니므로 Acyclic 입니다.
Airflow에서 ETL을 부르는 명칭
DAG는 태스크로 구성됨
- 예를 3개의 태스크로 구성된다면 Extract, Transform, Load로 구성
태스크란? - Airflow의 오퍼레이터(Operator)로 만들어짐
- Airflow에서 이미 다양한 종류의 오퍼레이터를 제공함
- 경우에 맞게 사용 오퍼레이터를 결정하거나 필요하다면 직접 개발
- e.g., Redshift writing, Postgres query, S3 Read/Write, Hive query, Spark job, shell script
DAG의 구성 예제 (1)

3개의 Task로 구성된 DAG입니다.
먼저 t1이 실행되고 t2, t3의 순으로 일렬(직렬)로 실행됩니다.
t1, t2, t3 모두 실행되면 DAG가 끝납니다. 태스크 단위로 스케줄이 된다는 점을 기억해주세요.
DAG의 구성 예제 (2)
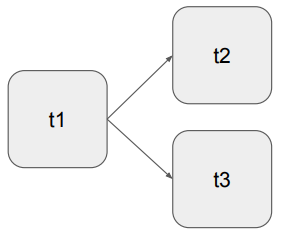
t1 그 다음 t2와 t3가 동시에 실행되는 병렬식 구성도 가능합니다.
t1이 끝나고 t2와 t3가 동시에 실행되어 t2, t3 두개도 실행이 끝나면 DAG가 끝납니다.
'Airflow' 카테고리의 다른 글
| Airflow 설치 개요 (0) | 2023.12.12 |
|---|---|
| Airflow - 숙제 리뷰와 트랜잭션 (0) | 2023.12.12 |
| Airflow 소개 (0) | 2023.12.11 |
| Airflow - ETL 실습 (0) | 2023.12.11 |
| Ariflow - 데이터 파이프라인을 만들 때 고려할 점 (0) | 2023.12.11 |