사용해볼 데이터 웨어하우스
Redshift dc2.large
- 2 CPU, 15GB memory, 160GB SSD
Host: (포트)
Port: 5439
Database: (DB 이름)
ID: 본인의 ID
이 ID로 스키마가 만들어져 있음
Password: 본인의 패스워드
raw_data, analytics, adhoc 3개의 스키마 이외에 자신의 ID로 만들어진 스키마가 하나 더 있습니다.
본인의 스키마는 본인만이 접근할 수 있고 앞으로의 실습은 이 스키마에서 진행하겠습니다.
Extract, Transform, Load

ETL을 데이터 파이프라인하며 Airflow에서는 DAG라고 지칭
Extract:
데이터를 데이터 소스에서 읽어내는 과정. 보통 API 호출
Transform:
필요하다면 그 원본 데이터의 포맷을 원하는 형태로 변경시키는 과정. 굳이 변환할 필요는 없음. Transform해야하는 데이터의 규모가 크다면 Spark 등을 사용
Load:
최종적으로 Data Warehouse에 테이블로 집어넣는 과정
ETL 실습 개요
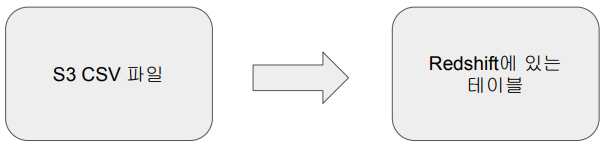
1. 웹상에 존재하는 이름, 성별 CSV 파일을 Redshift에 있는 테이블로 복사
2. Python으로 Google Colab에서 작성
ETL 개념으로 더 자세하게 설명하면
S3의 CSV 파일을 읽어 (Extract)
CSV 파일을 Redshift 테이블에 적재할 수 있도록 Google Colab에서 파이썬 코드를 작성해 포맷을 변경하고 (Transform)
Redshift 테이블에 적재합니다. (Load)
Redshift에 테이블 생성
웹상에(실습에서는 S3에) 존재하는 이름, 성별 CSV 파일을 Redshift에 있는 테이블로 복사할 겁니다.
그 전에 아래와 같이 테이블을 생성해주세요.
CREATE TABLE (본인의스키마).name_gender (
name varchar(32) primary key,
gender varchar(8)
);
여기서 다시 한번 짚고 넘어갑니다.
name 필드에 primary key가 정의되어 있지만 데이터 웨어하우스는 성능 보장을 위해 primary key uniqueness를 보장하지 않는다고 말씀드렸습니다.
이곳에서 Uniqueness를 보장하지 않는다는 점을 이곳에서 그러므로 데이터 엔지니어가 해야할 일에 대해 설명했었습니다. 익숙치 않다면 다시 확인해주세요.
CSV 파일 다운로드
데이터 소스:
(S3 URI)
파일에는 다음과 같이 필드 2개가 정의되어있습니다.
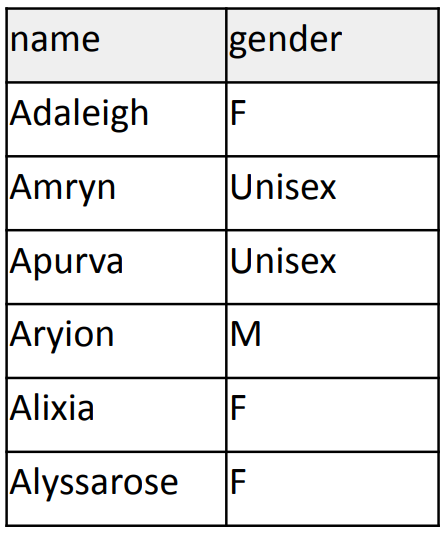
남자 이름으로 사용된다면 M, 여자의 경우는 F, 둘 다 사용할 수 있다면 Unisex입니다.
프로그램 구조
파이썬으로 Colab에서 작성: 세 개의 함수로 구성
extract, transform, load
3개의 함수를 각각 별개의 태스크(Airflow에서는 task 단위로 나누어 작업을 수행합니다.)로 구성할 수도 있고 하나의 태스크 안에서 3개의 함수를 모두 호출하게 구성할 수도 있습니다.

extract는 url을 인자로 받아 그대로 return
transform은 data를 인자로 받아 리스트로 return
load는 Redshift 테이블에 로드하는 함수입니다.
'Airflow' 카테고리의 다른 글
| Airflow - 숙제 리뷰와 트랜잭션 (0) | 2023.12.12 |
|---|---|
| Airflow 구성 (0) | 2023.12.11 |
| Airflow 소개 (0) | 2023.12.11 |
| Ariflow - 데이터 파이프라인을 만들 때 고려할 점 (0) | 2023.12.11 |
| Airflow - 데이터 파이프라인 (0) | 2023.12.09 |