
터칭 데이터
Superset - 만들어 볼 대시보드 소개 본문
만들어볼 두 개의 차트와 하나의 대시보드

1. 위와 같은 Key Metrics라는 이름의 대시보드를 만들겁니다.
2. 이 대시보드는 2개의 Chart로 이루어져 있습니다.
- 하나는 MAU, 다른 하나의 이름은 Cohort입니다.
3. Database로는 Redshift를 사용할겁니다.
채널별 Monthly Active User(MAU) 차트
- 입력 테이블(Dataset)은 analytics.user_session_summary
Monthly Cohort 차트
- 입력 테이블(Dataset)은 analytics.cohort_summary
MAU 차트 입력: user_session_summary
CREATE TABLE analytics.user_session_summary AS
SELECT usc.*, t.ts
FROM raw_data.user_session_channel usc
LEFT JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
user_session_channel의 모든 컬럼과 user_session_timestamp의 ts 컬럼을 합쳐 CTAS로 user_session_summary라는 테이블(여기서는 Dataset)을 만듭니다.
구글 스프레드시트로 해보는 MAU 시각화 (1)

아래 내용을 다운로드 받아 mau.csv로 저장
SELECT
LEFT(ts, 7) "month",
COUNT(DISTINCT userid) mau
FROM analytics.user_session_summary
GROUP BY 1
ORDER BY 1;
이 파일을 Google Spreadsheet로 로딩
이를 차트 기능을 사용해서 시각화 수행
구글 스프레드시트로 해보는 MAU 시각화 (2)
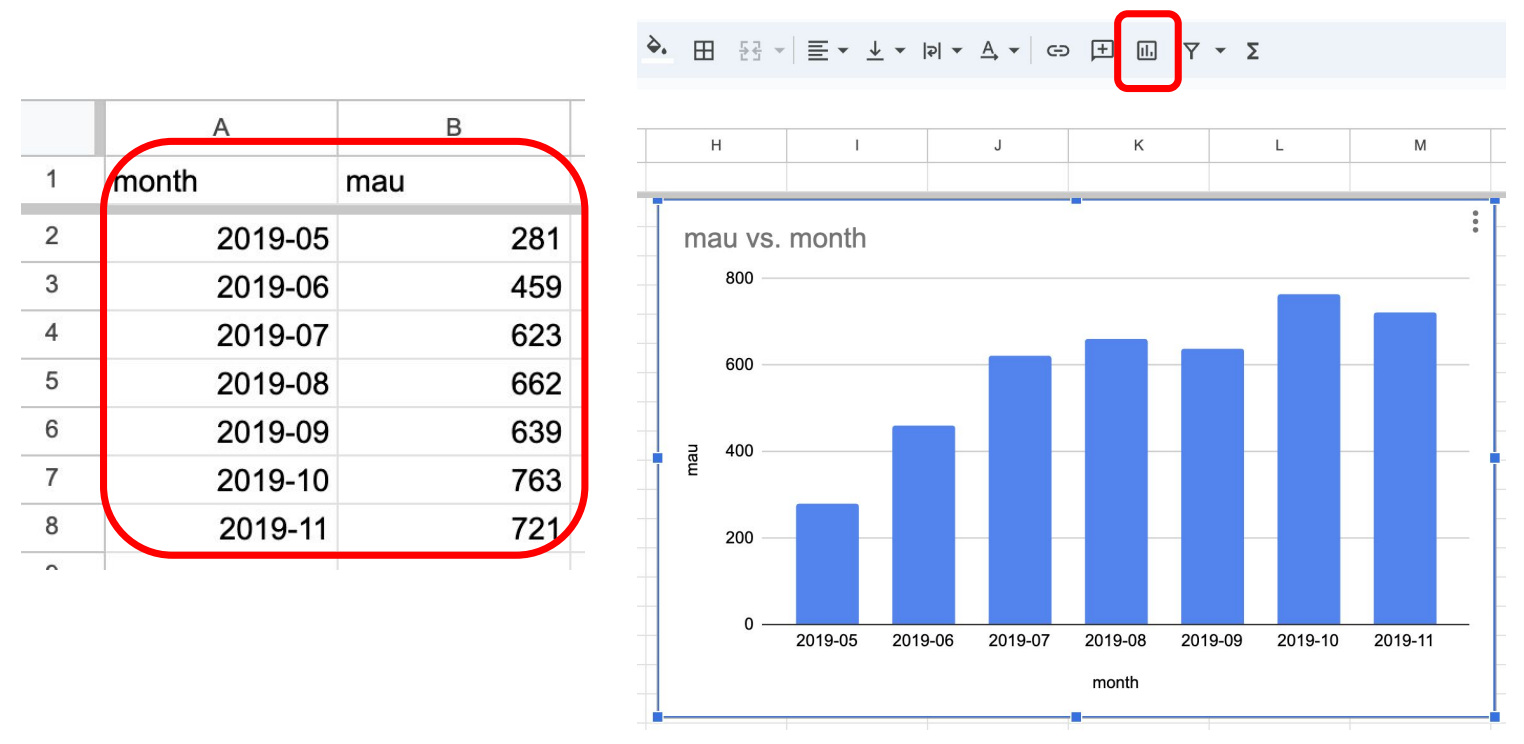
왼쪽의 SELECT 결과물을 오른쪽 구글 스프레드시프트의 기능을 이용해 차트화합니다.
코호트 분석이란?

굉장히 많이 듣게 될 단어
코호트(Cohort)란?
코호트는 같은 속성을 가진 사용자들을 의미합니다. 서비스 방문 관련 분석에서는 다음과 같이
- 특정 속성을 바탕으로 나뉘어진 사용자 그룹
- 보통 속성은 사용자의 서비스 등록월
두 가지로 월별로 분류하는 경우가 많습니다.
코호트 분석이란?
- 코호트를 기반으로 다음을 계산
- 사용자의 이탈률, 잔존률, 총 소비금액 등
코호트 기반 사용자 잔존률 (Retention)
- 보통 월기반으로 시각화해서보는 것이 일반적
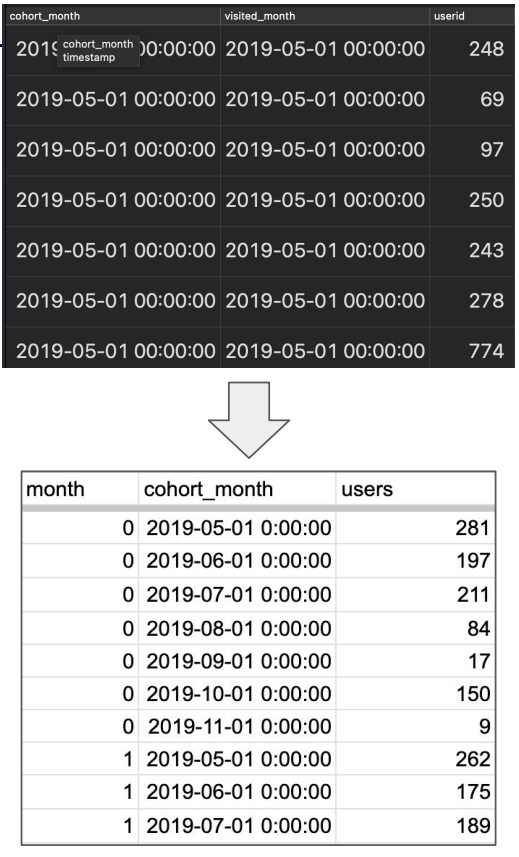
Cohort 차트 입력: cohort_summary
Cohort 분석을 위해 테이블을 만듭니다.
먼저 아래 Summary 테이블을 Redshift 단에 생성 - 이미 만들어져 있음
CREATE TABLE analytics.cohort_summary as
SELECT cohort_month, visited_month, cohort.userid
FROM (
SELECT userid, date_trunc('month', MIN(ts)) cohort_month
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
GROUP BY 1
) cohort
JOIN (
SELECT DISTINCT userid, date_trunc('month', ts) visited_month
FROM raw_data.user_session_channel usc
JOIN raw_data.session_timestamp t ON t.sessionid = usc.sessionid
) visit ON cohort.cohort_month <= visit.visited_month and cohort.userid = visit.userid;
사용자 ID별로 서비스를 처음 방문한 달과 그 이후 방문한 달들을 테이블로 만드는 쿼리입니다.
MAU와 Cohort 테이블은 Redshift의 analytics 스키마 밑에 이미 만들어져 있습니다.
만일 다른 백엔드를 사용한다면 위의 쿼리로 만들어주세요.
Snowflake 체험판을 Superset에서 연결하고 싶다면 Worksheet에서 analytics 스키마 밑에 위의 쿼리를 실행해 테이블을 만들어주세요.
구글 스프레드시트로 해보는 코호트 시각화 (1)
아래 내용을 다운로드 받아서 cohort.csv로 저장
SELECT
DATEDIFF(month, cohort_month, visited_month) month,
cohort_month,
COUNT(userid) users
FROM analytics.cohort_summary
GROUP BY 1, 2
ORDER BY 1, 2;
이 파일을 Google Spreadsheet로 로딩
이를 피봇 테이블 기능을 사용해서 시각화 수행
- 뒤에서 더 자세히 설명
구글 스프레드시트로 해보는 코호트 시각화 (2)

구글 스프레드시트에서 Pivot으로 회전하여 결과물을 조회
실습: 구글 스프레드시트로 해보는 MAU와 코호트 시각화
앞서 설명한 mau.csv와 cohort.csv의 내용을 가지고 만든 스프레드시트
Python에서는 gspread라는 모듈을 통해 구글 스프레드시트 조작을 코드로 가능
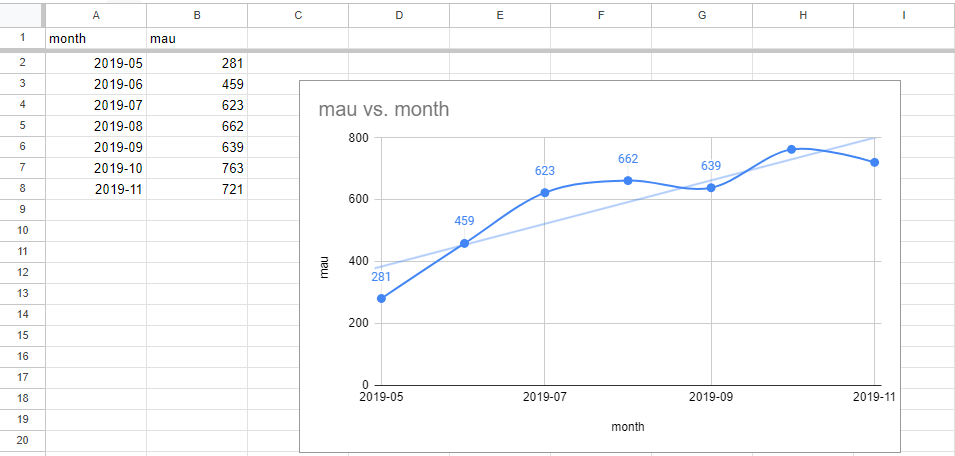
MAU

Cohort
'데이터 웨어하우스(Data Warehouse)' 카테고리의 다른 글
| Superset - Preset 셋업 (0) | 2023.12.01 |
|---|---|
| Superset 설치 방법 - Docker란? (0) | 2023.12.01 |
| Superset (0) | 2023.12.01 |
| 다양한 시각화 툴 (0) | 2023.12.01 |
| Snowflake 기타 기능과 사용 중단하기 (0) | 2023.11.30 |

