
터칭 데이터
Redshift 벌크 업데이트(COPY) - 1 본문
이번 COPY 실습의 목표
1. CREATE TABLE 명령으로 raw_data 스키마 밑에 테이블 3개를 생성합니다.
2. S3의 버킷을 생성합니다.
3. 만든 3개의 테이블들에 입력할 레코드(데이터)들이 담긴 CSV파일을 S3 버킷에 복사합니다.
4. INSERT INTO가 아닌 COPY 명령을 사용해 raw_data 스키마 밑에 있는 3개의 테이블들에 S3에 복사된 CSV파일들의 데이터들을 벌크 업데이트 합니다.
5. 이 때 주의할 점은 Redshift가 CSV파일이 담긴 S3버킷에 접근할 수 있도록 권한을 세팅하고 부여해줘야 합니다. 이때 IAM을 사용할 것입니다.
1. raw_data 스키마에 테이블 만들기
지난 시간 raw_data 스키마는 외부의 데이터들을 ETL을 이용해 읽어온 데이터를 저장하기 위한 곳이라고 했었죠?
CREATE TABLE raw_data.user_session_channel (
userid integer ,
sessionid varchar(32) primary key,
channel varchar(32)
);
CREATE TABLE raw_data.session_timestamp (
sessionid varchar(32) primary key,
ts timestamp
);
CREATE TABLE raw_data.session_transaction (
sessionid varchar(32) primary key,
refunded boolean,
amount int
);
만들 테이블 3개는 위와 같습니다.
2. S3 버킷 생성과 파일 업로드
CSV 파일들을 다운 받습니다.
user_session_channel.csv
session_timestamp.csv
session_transaction.csv
그리고 AWS 콘솔에서 S3 bucket을 하나 만들고 CSV파일들을 업로드할 것입니다.
s3://devjon-test-bucket/test_data/user_session_channel.csv
raw_data.user_session_channel
s3://devjon-test-bucket/test_data/session_timestamp.csv
raw_data.session_timestamp
s3://devjon-test-bucket/test_data/session_transaction.csv
raw_data.session_transaction
devjon-test-bucket이라는 버킷을 만들고 그 밑에 test_data라는 폴더를 만든 뒤 3개의 파일들을 각각 업로드할 것입니다. 3개의 파일들은 raw_data 스키마에서 생성한 3개의 테이블에 대응합니다.
devjon-test-bucket의 버킷 이름은 유니크해야 합니다. 이점 유의해 버킷의 이름을 정해주세요.
3. Redshift에 S3 접근 권한 설정
조금 까다로운 부분입니다.
Redshift가 앞서 만든 S3 버킷에 접근할 수 있어야 합니다.
이 때 AWS IAM(Identity and Access Management)을 이용해 이에 해당하는 역할(Role)을 만들고 이를 Redshift에 부여해야 합니다.
주의하실 점은 AWS IAM의 Role과 바로 이전 시간에서 살펴본 Redshift의 RBAC(Role-Based Access Control)에서의 Role은 비슷한 컨셉이기는 하지만 전혀 다르다는 것을 기억해주세요
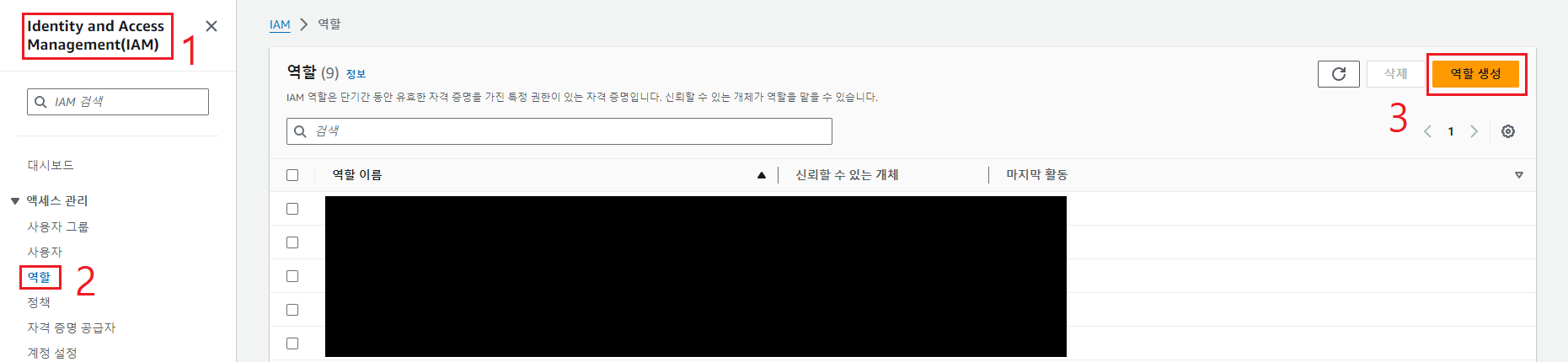
1. AWS 웹 콘솔에 로그인한 후 IAM에 방문합니다.
2. 역할(Roles)를 클릭합니다.
3. 주황색 버튼 역할 생성을 클릭합니다.

위와 같이 선택한 후 다음을 클릭해주세요.

S3로 검색 후 AmazonS3FullAccess를 선택한 뒤 다음 버튼을 클릭합니다.
참고로 훗날 여러분이 S3에 대해 읽기 전용(ReadOnly)권한만 부여하고 싶다면 초록색 박스를 선택하시면 됩니다.

역할의 이름을 입력해야 합니다.
우리는 이번 실습에서 역할의 이름을 redshift.read.s3로 짓겠습니다.
역할의 이름은 꼭 기억해주셔야 합니다.
redshift.read.s3
그리고 우측 하단의 역할 생성 버튼을 클릭해주세요.
이제 역할을 생성했으니 생성한 역할을 Redshift에 지정해 권한을 부여하면 됩니다.

Redshift 대시보드에서 우리가 실습으로 사용중인 클러스터의 네임스페이스를 클릭합니다.

보안 및 암호화(Security and encryption)탭의 IAM 역할 관리(Manage IAM roles)버튼을 클릭합니다. 버튼 2개 중 어떤 것을 클릭하셔도 상관 없습니다.

IAM 역할 연결을 선택합니다.

그리고 우리가 방금 생성한 redshift.read.s3 역할을 선택한 뒤 연결해주세요.
자 끝났습니다.
우리가 실습에 사용중인 Redshift 클러스터는 이제 S3에 Full access 권한을 부여 받았습니다.
4. COPY 명령으로CSV 파일들을 테이블로 복사
raw_data 스키마 아래 생성한 테이블 3개에 CSV파일들을 벌크 업데이트할 것입니다.
이를 위해서는 COPY SQL 커맨드를 사용합니다.
COPY SQL 문법이 꽤 까다롭습니다. 나중에 하단의 링크도 한번 참고해주세요.
https://docs.aws.amazon.com/redshift/latest/dg/r_COPY.html
COPY - Amazon Redshift
Amazon Redshift Spectrum external tables are read-only. You can't COPY to an external table.
docs.aws.amazon.com
COPY raw_data.user_session_channel
FROM 's3://devjon-test-bucket/test_data/user_session_channel.csv'
credentials 'aws_iam_role=arn:aws:iam:xxxxxxx:role/redshift.read.s3'
delimiter ',' dateformat 'auto' timeformat 'auto' IGNOREHEADER 1 removequotes;
테이블이 3개이므로 위의 형식의 쿼리를 3번 실행할겁니다. 그전에 쿼리에 대해 설명을 하겠습니다.
COPY 뒤에 목적지가 되는 스키마의 테이블(raw_data.user_session_channel)을 명시해줍니다.
FROM 뒤에는 S3에 있는 CSV파일의 위치를 명시합니다.
(devjon-test-bucket이라는 버킷의 test_data 폴더의 user_session_channel.csv 파일입니다.)
CSV 파일이므로 delimiter를 콤마(,)로 지정합니다.
CSV 파일의 첫줄은 헤더이므로 IGNOREHEADER 1을 입력합니다.
CSV 파일에서 문자열이 따옴표로 둘러싸인 경우 이를 제거하기 위해 removequotes를 지정합니다.
dateformat과 timeformat은 'auto'로 지정해 Redshift가 알아서 찾도록 합니다.
Credentials
credentials에는 우리가 Redshift의 S3 접근 권한을 위해 생성해준 redshift.read.s3의 ARN을 적어줘야 합니다. 우리가 IAM을 이용해 역할을 생성해 권한을 부여해준 이유가 바로 여기있습니다.
ARN은 Amazon Resource Number의 약자입니다.
여기서 궁금하실겁니다.
ARN은 어디서 확인하지?
Redshift 대시보드에서 S3에 접근해야하는 Redshift 클러스터의 네임스페이스 링크를 클릭합니다.

보안 및 암호화 탭을 클릭하면 권한에서
왼쪽의 redshift.read.s3는 아까 우리가 지어준 이름입니다. 이는 사람이 식별할 수 있는 역할 이름입니다.
그리고 오른쪽에 가려진 ARN이 바로 COPY의 credentials에서 필요한 ARN입니다. ARN은 readshift.read.s3와 달리 컴퓨터가 식별할 수 있기 때문에 이를 활용합니다.
아니면 IAM의 역할(Roles)의 redshift.read.s3 링크를 클릭해 확인할 수도 있습니다.
만일 COPY 명령 중 에러가 났다면?
SELECT * FROM stl_load_errors ORDER BY starttime DESC;
starttime을 기준으로 내림차순한 이유는 대개 가장 최근에 낸 에러를 확인하기 편하기 때문입니다. LIMIT도 같이 사용하시면 좋습니다.
어떤 필드에서 에러가 발생했는지 확인할 수 있습니다.
흔히 발생하는 에러의 예시는 다음과 같습니다.
CSV파일의 특정 컬럼의 타입이 문자열인데 해당하는 테이블의 필드가 INT이거나 특정 컬럼의 타입이 문자열인데 테이블 타입의 길이가 충분치 않은 경우가 많습니다.
analytics 스키마에 테스트 테이블 만들기
벌크 업데이트 실습과 함께 아주 간단한 ELT를 해보려 합니다.
raw_data나 anlaytics 스키마 아래의 테이블들을 이용해 새로운 테이블을 analytics에 생성하는 실습을 할겁니다. 어딘가 익숙한 개념이지 않나요? 우리가 지난 시간 살펴본 ELT의 개념이 바로 이것입니다.
보통은 DBT(Data build tool)라는 툴을 가장 많이 사용하지만 이번에는 간단하게 CATS를 사용하겠습니다.
CREATE TABLE analytics.mau_summary AS
SELECT
TO_CHAR(A.ts, 'YYYY-MM') AS month,
COUNT(DISTINCT B.userid) AS mau
FROM raw_data.session_timestamp A
JOIN raw_data.user_session_channel B ON A.sessionid = B.sessionid
GROUP BY 1
ORDER BY 1 DESC;
'데이터 웨어하우스(Data Warehouse)' 카테고리의 다른 글
| Redshift 권한 (0) | 2023.11.29 |
|---|---|
| Redshift 벌크 업데이트(COPY) - 2 (0) | 2023.11.28 |
| Redshift 초기 설정개념과 실습 (0) | 2023.11.28 |
| Redshift 설치와 Colab 연결 (0) | 2023.11.28 |
| Redshift의 기본 데이터 타입과 주의할 점 (0) | 2023.11.28 |


