
터칭 데이터
Redshift 초기 설정개념과 실습 본문
Redshift 초기 설정
Redshift를 처음 구동하면 스키마, 그룹, 유저, 역할 등을 생성해야 합니다. 이에 대해 알아보겠습니다.
Redshift Schema

Redshift의 Schema는 테이블들이나 뷰들을 목적과 용도에 맞게 분류할 수 있는 폴더 기능입니다.
다른 기타 관계형 데이터베이스와 동일한 구조입니다.
이번 실습에서는 위의 이미지와 같이 4개의 Schema를 만들어보려 합니다.
raw_data: 외부에 있는 데이터들을 테이블 형태로 저장
analytics: 기존의 테이블을 조합해 만들어진 ELT 테이블을 저장
adhoc: 테스트용 테이블을 저장
pii: 개인정보 저장, 매우 위험하고 민감한 정보이므로 사용과 접근 권한자를 최소화하고 logging 기능을 추가
스키마 이름만 보아도 어떤 테이블이 있는지 알 수 있도록 하는 것이 좋습니다.
그리고 테이블들이 스키마 안에 존재하기 때문에 Schema이름.테이블이름과 같이 어떤 스키마에 있는지를 테이블 이름앞에 온점과 함께 사용해야 테이블을 이용할 수 있습니다.
스키마(Schema) 설정
CREATE SCHEMA raw_data;
CREATE SCHEMA analytics;
CREATE SCHEMA adhoc;
CREATE SCHEMA pii;
스키마를 생성하는 쿼리는 위와 같습니다.
Redshift에 접근 가능한 사용자에게 admin 권한이 있어야 CREATE SCHEMA를 실행할 수 있습니다.
select * from pg_namespace;
모든 스키마를 리스트하기
사용자(User) 생성
CREATE USER jon PASSWORD '...';
따옴표 사이에 패스워드를 입력하시면 됩니다.
기본적으로는 8자 이상의 숫자, 대소문자와 특수문자 각각 1개 이상 등의 제약조건이 있습니다.
select * from pg_user;
모든 사용자를 리스트하기
그룹(Group) 생성/설정 (1)
테이블이 수천 개, 사용자가 수백 명인 상황을 상상해봅시다. 어떤 사용자에게 어떤 테이블에 대해 어떤 권한을 줄지 관리하기 매우 힘듭니다.
이 때 테이블별이 아닌 스키마별로, 사용자별이 아닌 그룹을 생성한 뒤 그룹별로 관리하면 훨씬 관리가 쉬우며 이런 방식이 일반적입니다.
테이블이 1000개라고 해도 스키마가 4개라면 4개의 스키마만 관리하면 됩니다. 사용자가 1만명이라고 해도 그룹이 5개라면 5개의 그룹만 관리하면 됩니다.
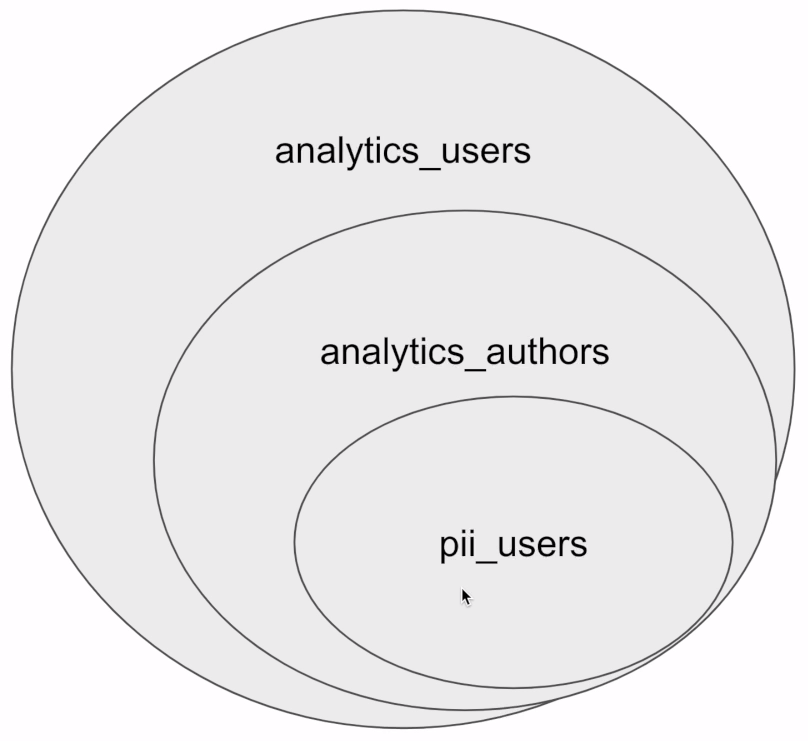
위와 같이 3개의 그룹이 존재한다고 가정해보겠습니다.
analytics_users: 데이터를 select로 조회만 할 수 있는 그룹
analytics_authors: ELT 등 새로운 테이블을 만들 수 있는 데이터 분석가를 위한 그룹
pii_users: 매우 민감한 개인정보에 접근할 수 있는 소수의 admin을 위한 그룹
한 사용자는 다수의 그룹에 속할 수 있습니다.
위의 그림을 보시면 pii_users는 analytics_users와 analytics_authors의 그룹들에도 속해 있다고 보실 수 있습니다.
그룹은 계승이 안된다는 문제가 있습니다.
객체지향 프로그래밍(OOP)에서의 클래스를 상속하는 것처럼
analytics_users의 권한을 계승해 analytics_authors에만 필요한 새로운 권한을 정의하거나
analytics_authors의 권한을 계승해 pii_users에게만 필요한 권한을 정의할 수 있다면 매우 편하겠지만 불가능합니다.
analytics_users에 주었던 권한을 다시 정의해 analytics_authors의 권한을 지정하고
analytics_authors에 주었던 권한을 다시 정의해 pii_users의 권한을 지정하는 방식만 가능합니다.
즉 그룹이 많아질수록 그룹을 관리하기가 매우 힘들어집니다.
이를 해결하기 위해 등장하는 것이 역할(Role)입니다
Role은 그룹과 같지만 계승이 가능해 관리가 쉽습니다.
일단은 그룹을 어떻게 사용하는지 먼저 알아보겠습니다.
그룹(Group) 생성/설정 (2)
CREATE GROUP analytics_users;
CREATE GROUP analytics_authors;
CREATE GROUP pii_users;
ALTER GROUP analytics_authors ADD USER (사용자 이름);
ALTER GROUP analytics_users ADD USER (사용자 이름);
ALTER GROUP pii_users ADD USER (사용자 이름);
그룹 생성 - CREATE GROUP
그룹에 사용자 추가 - ALTER GROUP 그룹이름 ADD USER 사용자이름
그룹에 스키마/테이블 접근 권한 설정 (나중에 Grant 문법에 대해 설명)
select * from pg_group;
모든 그룹을 리스트하기
역할(Role) 생성/설정
CREATE ROLE staffs;
CREATE ROLE managers;
CREATE ROLE externals;
GRANT ROLE staffs TO Jon; # Jon이라는 사용자에게 staffs라는 역할을 부여
GRANT ROLE staffs TO ROLE managers; # staffs라는 역할을 managers라는 역할에게 부여(상속 or 계승)
역할은 그룹과 달리 계승 구조를 만들 수 있음
역할은 사용자에게 부여될 수도 있고 다른 역할에 부여될 수도 있음
한 사용자는 다수의 역할에 소속가능함
위에서 마지막 쿼리는 주석의 설명 그대로 staffs라는 역할을 managers라는 역할에 계승한다는 뜻입니다.
managers 뒤에 어떠한 권한들을 새로 확장시킬지 별도로 쿼리문을 더 작성할 수 있습니다.
select * from SVV_ROLES;
모든 역할을 리스트하기
구글 코랩(Colab)에서 실습 - 연결하기
%load_ext sql
!pip install ipython-sql==0.4.1
!pip install SQLAlchemy==1.4.49
실습을 진행한 시점에서는 ipython-sql과 SQLAlchemy 라이브러리의 compatibility 문제로 위와 같이 버전을 지정해 설치했으니 이 점 유의해주시기 바랍니다.
그리고 위의 pip install 실행결과에서 Restart runtime이라는 문구가 뜬다면 반드시 런타임을 다시 시작해야 합니다.
%sql postgresql://(관리자 사용자 이름):(패스워드)@(엔드 포인트)
코랩에서 Redshift 연결을 위해서는 위와 같이 3가지 정보가 필요합니다.
코랩 실습 - 스키마 생성하기
%%sql
CREATE SCHEMA raw_data;
CREATE SCHEMA analytics;
CREATE SCHEMA adhoc;
CREATE SCHEMA pii;
스키마를 처음 생성하신다면 위와 같이 뜰 것입니다.
%%sql
select * from pg_namespace;

select * from pg_namespace;로 모든 스키마들을 조회할 수 있다고 했었습니다.
그런데 우리가 방금 생성한 빨간색 박스의 4개의 스키마들외에도 다른 9개의 스키마들이 있는데 이는 Redshift에서 기본적으로 같이 생성한 스키마들입니다. 이들 중 몇가지는 추후에 사용하며 설명하겠습니다.
일단은 파란색 박스의 public은 테이블을 생성할 때 스키마 이름 없이 생성한 즉, 스키마이름.테이블이름처럼 어떤 스키마에 생성할지 명시하지 않은 테이블들을 보관하는 곳이라는 것을 기억해주세요.
코랩 실습 - User 생성
%%sql
CREATE USER jon PASSWORD '....'
jon이라는 이름의 사용자를 생성했습니다. 따옴표 사이의 패스워드는 8글자 이상이어야 합니다.
%%sql
select * from pg_user;
모든 사용자들을 조회했습니다.
우리가 Redshift 클러스터 생성시 만들어진 admin과 방금 만든 jon외에도
rdsdb와 IAM:RootIdentity라는 사용자가 있음을 볼 수 있습니다.
코랩 실습 - Group 생성
%%sql
CREATE GROUP analytics_users;
CREATE GROUP pii_users;
일단 analytics_users와 pii_users라는 그룹을 생성했습니다.
%%sql
ALTER GROUP analytics_users ADD USER jon;
ALTER GROUP pii_users ADD USER jon;
아까 만든 jon이라는 사용자를 방금 만든 그룹에 추가했습니다.
%%sql
CREATE GROUP analytics_authors;
ALTER GROUP analytics_authors ADD USER jon;
그런데 우리가 Group의 개념을 살펴봤을 때 보았던 예시에는 analytics_authors라는 그룹도 있었죠?
새로 그룹을 생성함과 동시에 사용자를 그룹에 추가해 보았습니다.
코랩 실습 - Role 생성
%%sql
CREATE ROLE staff;
CREATE ROLE manager;
CREATE ROLE external;
staff, manager, external 역할들을 생성했습니다.
%%sql
GRANT ROLE staff TO jon;
GRANT ROLE staff TO ROLE manager;
첫줄은 staff라는 역할을 jon이라는 사용자에게 지정
둘째줄은 staff라는 역할을 ROLE을 이용해 manager라는 역할에게 지정
%%sql
select * from SVV_ROLES;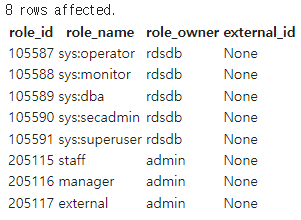
어떤 역할들이 있는지는 SVV_ROLES에서 조회가 가능합니다.
'데이터 웨어하우스(Data Warehouse)' 카테고리의 다른 글
| Redshift 벌크 업데이트(COPY) - 2 (0) | 2023.11.28 |
|---|---|
| Redshift 벌크 업데이트(COPY) - 1 (0) | 2023.11.28 |
| Redshift 설치와 Colab 연결 (0) | 2023.11.28 |
| Redshift의 기본 데이터 타입과 주의할 점 (0) | 2023.11.28 |
| Redshift 벌크 업데이트 COPY (0) | 2023.11.28 |

