JVM Python
Spark 고급과 Spark ML
Shuffling시 Skew 처리방식과 Spark ML에 대해 배워보자
Contents
1. 기타 기능/개념 살펴보기
2. Driver와 Executor 해부
3. 메모리 이슈 정리
4. JVM과 Python 간의 통신
5. Caching과 Persist
6. Dynamic Partition Pruning
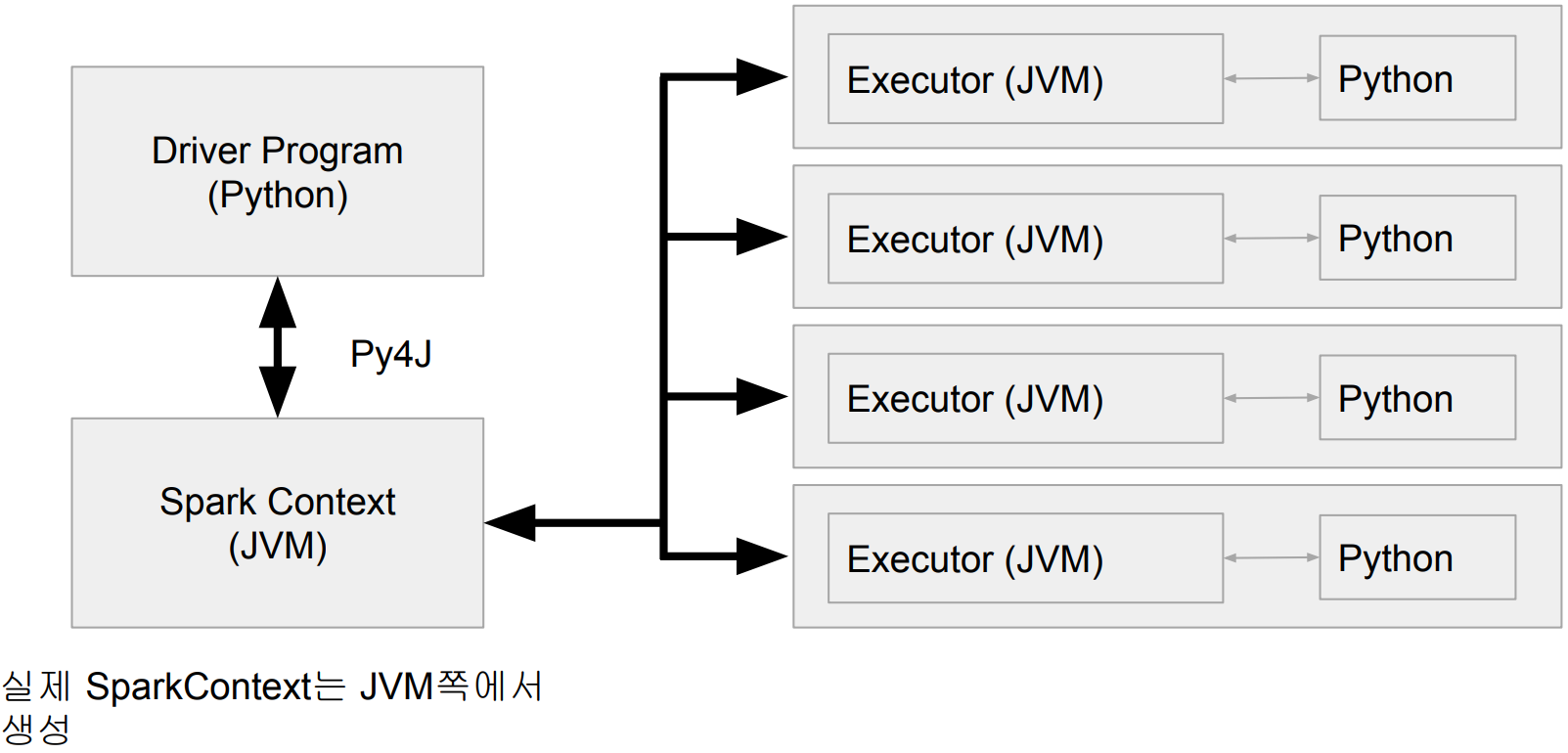
JVM과 Python 간의 통신
JVM과 Python 프로세스들간의 통신에 대해서 알아보자
PySpark Driver
Python 프로세스 + JVM 프로세스
PySpark Memory (1)
Spark은 JVM Application이지만 PySpark은 Python 프로세스
● JVM에서 바로 동작하지 못함 따라서 JVM 메모리를 사용할 수 없음
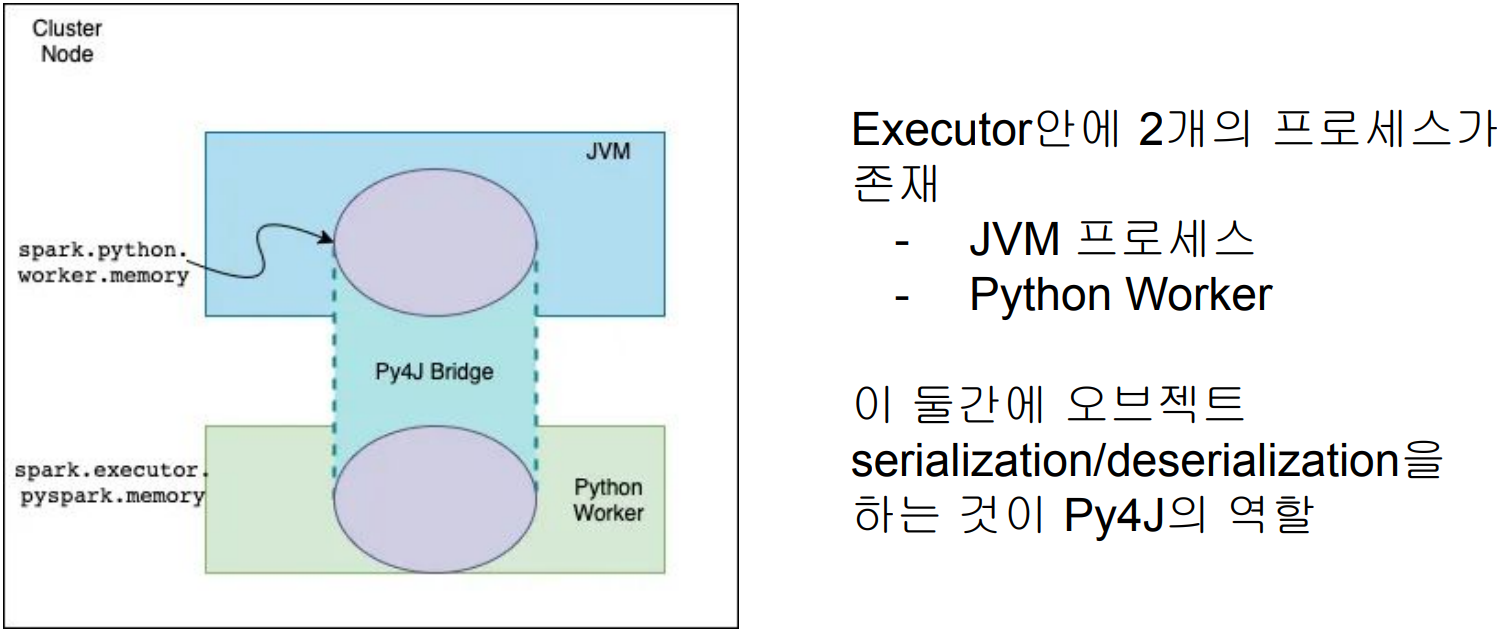
spark.executor.pyspark.memory (Python 프로세스)
spark.python.worker.memory (Py4J)
PySpark Memory (2)
spark.executor.pyspark.memory
● PySpark은 기본으로 overhead memory를 사용. 이 환경변수가 사용되면 PySpark이 사용할 수 있는 메모리는 이 환경변수의 값으로 고정됨
● 이는 사실 PySpark이 외부 파이썬 함수를 쓰는 경우에만 필요 (기본적으로는 세팅되지 않음)
spark.python.worker.memory
● 디폴트 값은 512MB (512m)
● JVM과 파이썬 프로세스간의 통신을 담당하는 Py4J가 사용할 수 있는 메모리의 양
● 이 크기를 넘어가면 디스크로 Spill 발생
● spark.executor.pyspark.memory는 파이썬 프로세스의 사용 메모리 크기 결정
● spark.python.worker.memory는 JVM에서 사용되는 파이썬 오브젝트들의 최대 메모리
결정
Spark과 Python간의 통신
Py4J: 파이썬과 JVM간의 데이터 교환을 통해 둘간의 연동을 도와주는 프레임웍
DataFrame/RDD 연산중에 파이썬 코드가 사용되면?
● 이는 별도의 파이썬 프로세스를 통해 실행되며 이 경우 파티션 데이터가 모두 넘어감

Spark과 UDF

Java나 Scala로 작성
Python으로 작성
Pandas Python으로 작성
● Vectorized UDFs
● PyArrow가 사용됨