
하둡과 Spark
Spark EMR 론치
터칭 데이터
2024. 1. 22. 12:16
Contents
1. AWS Spark 클러스터 론치
2. AWS Spark 클러스터 상에서 PySpark 잡 실행
AWS Spark 클러스터 론치
AWS EMR을 통해 Spark 클러스터를 론치해보자
AWS에서 Spark을 실행하려면
EMR (Elastic MapReduce) 위에서 실행하는 것이 일반적
EMR이란?
● AWS의 Hadoop 서비스 (On-demand Hadoop)
▪ Hadoop (YARN), Spark, Hive, Notebook 등등이 설치되어 제공되는 서비스
● EC2 서버들을 worker node로 사용하고 S3를 HDFS로 사용
● AWS 내의 다른 서비스들과 연동이 쉬움 (Kinesis, DynamoDB, Redshift, …)
Spark on EMR 실행 및 사용 과정
AWS의 EMR (Elastic MapReduce - 하둡) 클러스터 생성
EMR 생성시 Spark을 실행 (옵션으로 선택)
● S3를 기본 파일 시스템으로 사용
EMR의 마스터 노드를 드라이버 노드로 사용
● 마스터 노드를 SSH로 로그인
▪ spark-submit를 사용
● Spark의 Cluster 모드에 해당

Spark 클러스터 매니저와 실행 모델 요약
스텝 1. EMR 서비스 페이지로 이동
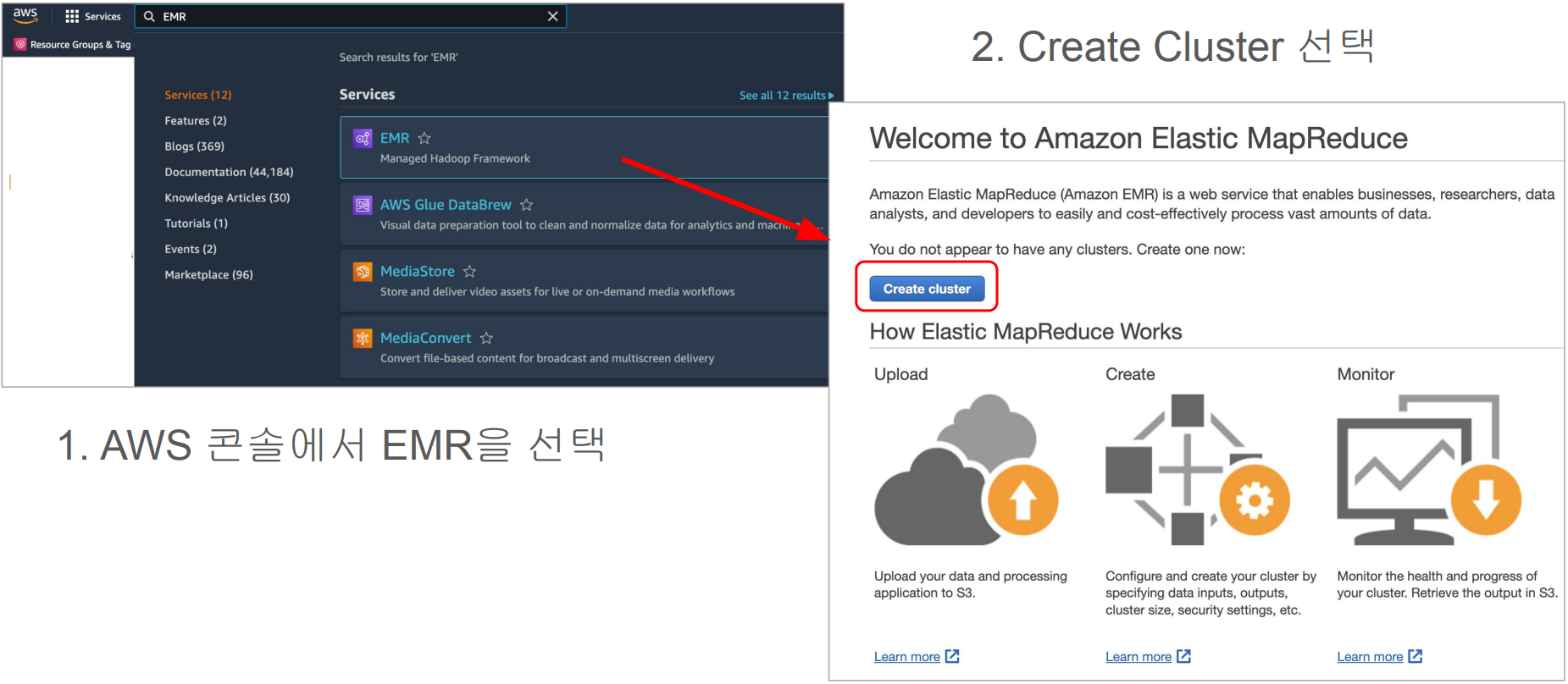
스텝 2: EMR 클러스터 생성하기 - 이름과 기술 스택 선택
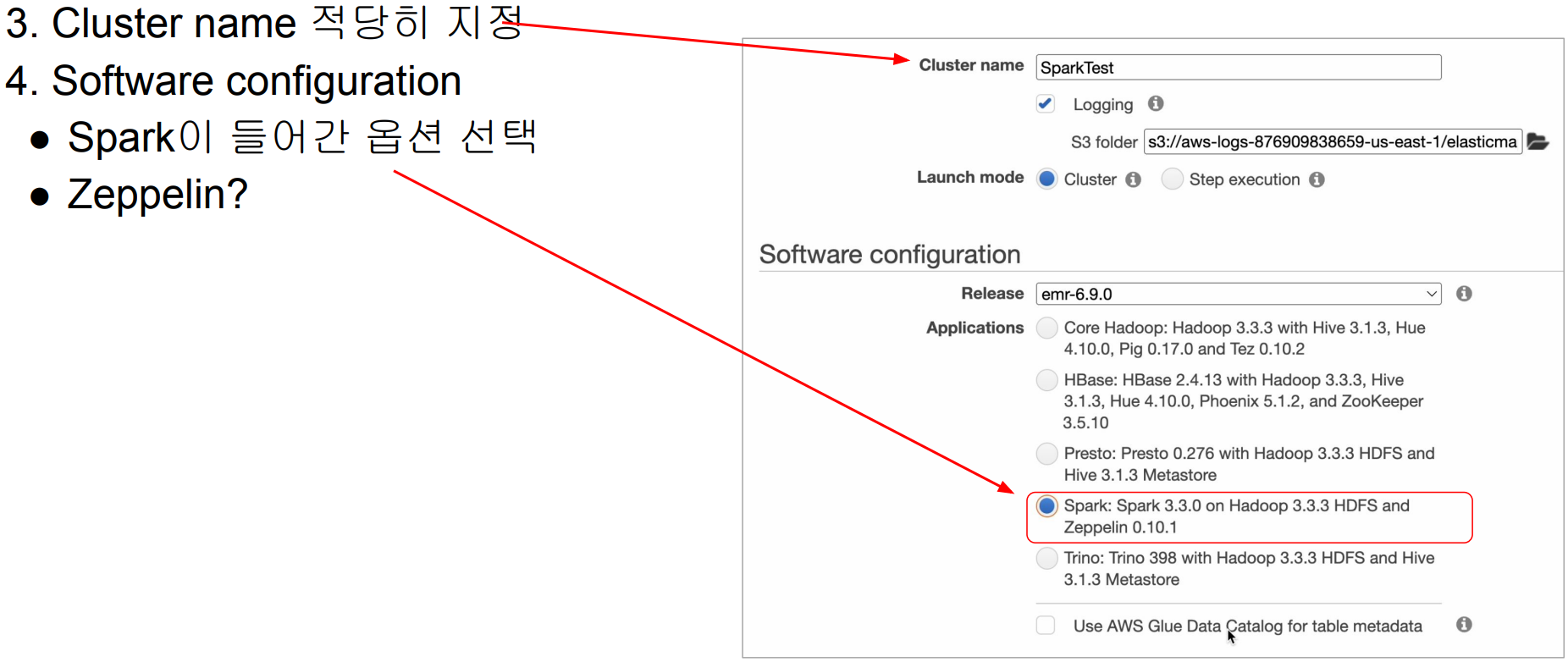
Zeppelin이란?
https://zeppelin.apache.org/: 노트북 (Spark, SQL, Python)

스텝 3: EMR 클러스터 생성하기 - 클러스터 사양 선택 후 생성

스텝 4: EMR 클러스터 생성까지 대기

마스터 노드의 포트번호 22번 열기 (1)

마스터 노드의 포트번호 22번 열기 (2)
Security Groups 페이지에서 마스터 노드의 security group ID를 클릭
Edit inbound rules 버튼 클릭 후 Add rule 버튼 선택
포트번호로 22를 입력, Anywhere IP v4 선택, Save rules 버튼 선택

스텝 5: Spark History Server 보기
