실습에 사용할 테이블에 대한 설명
◆ 관계형 데이터베이스 예제 - 웹서비스 사용자/세션 정보 (1)
❖ 사용자 ID: 보통 웹서비스에서는 등록된 사용자마다 부여하는 유일한 ID
❖ 세션 ID: 세션마다 부여되는 ID
● 세션: 사용자의 방문을 논리적인 단위로 나눈 것
▪ 사용자가 외부 링크(보통 광고)를 타고 오거나 직접 방문해서 올 경우 세션을 생성
▪ 사용자가 방문 후 30분간 interaction이 없다가 뭔가를 하는 경우 새로 세션을 생성
● 즉 하나의 사용자는 여러 개의 세션을 가질 수 있음
● 보통 세션의 경우 세션을 만들어낸 접점(경유지)를 채널이란 이름으로 기록해둠
▪ 마케팅 관련 기여도 분석을 위함
● 또한 세션이 생긴 시간도 기록
◆ 관계형 데이터베이스 예제 - 웹서비스 사용자/세션 정보 (2)
❖ 이 정보를 기반으로 다양한 데이터 분석과 지표 설정이 가능
● 마케팅 관련, 사용자 트래픽 관련
● DAU, WAU, MAU등의 일주월별 Active User 차트
● Marketing Channel Attribution 분석
▪ 어느 채널에 광고를 하는 것이 가장 효과적인가?
◆ 관계형 데이터베이스 예제 - 웹서비스 사용자/세션 정보 (3)
❖ 사용자 ID 100번: 총 3개의 세션(파란 배경)을 갖는 예제
● 세션 1: 구글 키워드 광고로 시작한 세션
● 세션 2: 페이스북 광고를 통해 생긴 세션
● 세션 3: 네이버 광고를 통해 생긴 세션


테이블은 2개입니다. 테이블의 컬럼(필드)과 타입은 위와 같습니다.

첫번째 테이블 user_session_channel입니다. 유저가 어떤 세션들을 갖고 어떤 채널을 통해 접속했는지 파악합니다. user 1명이 여러개의 session을 가질 수 있다고 했으므로 만일 이 테이블에서 Primary Key를 정해준다면 sessionId 필드가 적합합니다.
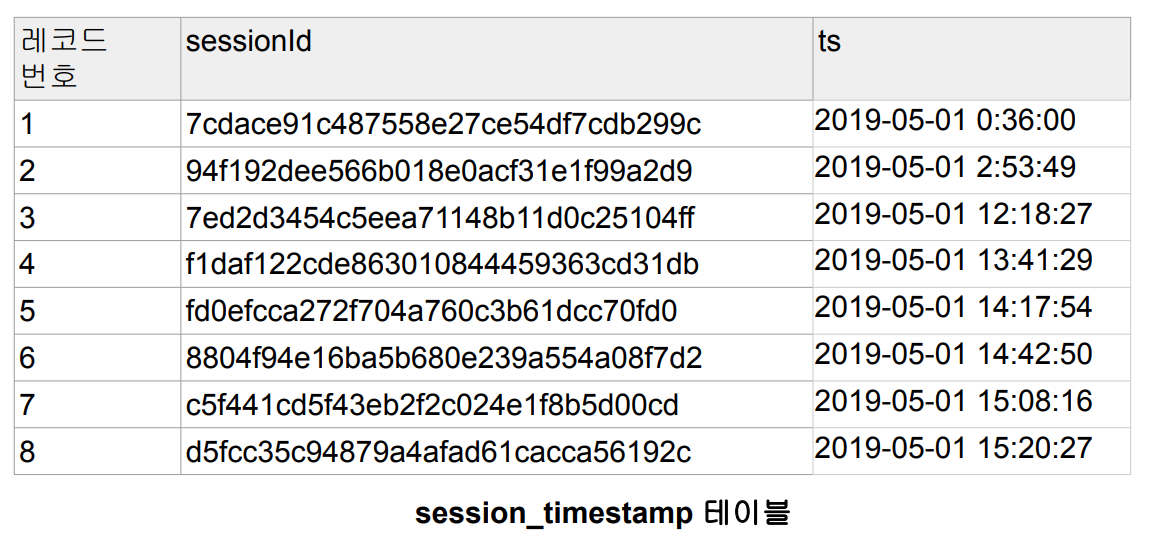
두번째 테이블 session_timestamp입니다. 각 세션이 생성된 시간이 언제인지 timestamp 필드를 통해 확인할 수 있습니다.
SELECT
Redshift의 SELECT 구문은 기존의 프로덕션 데이터베이스와 거의 동일합니다.
SELECT와 여러 조건 입력시 기본 순서
SELECT 필드이름1, 필드이름2, …
FROM 테이블이름
WHERE 선택조건
GROUP BY 필드이름1, 필드이름2, ...
ORDER BY 필드이름 [ASC|DESC] -- 필드 이름 대신에 숫자 사용 가능
LIMIT N;
SELECT, FROM, WHERE, GROUP BY, ORDER BY, LIMIT의 순서를 지켜주세요.
DISTINCT
SELECT DISTINCT channel -- 유일한 채널 이름을 알고 싶은 경우
FROM raw_data.user_session_channel;
COUNT
SELECT channel, COUNT(1) -- 채널별 카운트를 하고 싶은 경우. COUNT
함수!!
FROM raw_data.user_session_channel
GROUP BY 1;
한가지 질문을 드립니다. COUNT()는 Null value를 포함할까요?
이곳에 간단하게 정리가 되어있으므로 한번 읽어보시길 권장합니다.
CASE WHEN
필드 값의 변환을 위해 사용 가능
CASE WHEN 조건 THEN 참일때 값 ELSE 거짓일때 값 END 필드이름
여러 조건을 사용하여 변환하는 것도 가능
CASE
WHEN 조건1 THEN 값1
WHEN 조건2 THEN 값2
ELSE 값3
END 필드이름
SELECT CASE
WHEN channel in ('Facebook', 'Instagram') THEN 'Social-Media'
WHEN channel in ('Google', 'Naver') THEN 'Search-Engine'
ELSE 'Something-Else'
END channel_type
FROM raw_data.user_session_channel;
WHERE
LIKE와 ILIKE
SQL의 LIKE는 문자열 데이터의 패턴을 매칭합니다.
LIKE는 대소문자를 구분, ILIKE는 대소문자를 구분하지 않습니다.
%(Percent) 문자의 아무 순서나 매칭
SELECT COUNT(1)
FROM raw_data.user_session_channel
WHERE channel in
('Google','Facebook');SELECT DISTINCT channel
FROM raw_data.user_session_channel
WHERE channel ILIKE '%o%';
_(Underscore) 아무 단일 문자를 매칭
SELECT COUNT(1)
FROM raw_data.user_session_channel
WHERE channel ilike 'Google' or
channel ilike 'Facebook';
SELECT DISTINCT channel
FROM raw_data.user_session_channel
WHERE channel NOT ILIKE '%o%';
'SQL' 카테고리의 다른 글
| Redshift - CTAS & CTE, 테이블(데이터) 품질 확인 방법 (0) | 2023.11.15 |
|---|---|
| Redshift - GROUP BY & Aggregate 함수 (0) | 2023.11.15 |
| Redshift Cluster 생성 & Colab에 연결 (0) | 2023.11.14 |
| Redshift: Scalable SQL 엔진 (0) | 2023.11.12 |
| 클라우드와 AWS (0) | 2023.11.12 |