
터칭 데이터
Spark 소개 본문
Spark 소개
하둡은 1세대 빅데이터 처리기술이라면 Spark은 2세대 빅데이터 기술이라 할 수 있다.
이번 강의 주제인 Spark에 대해 알아보자
Spark의 등장
사실상의 표준 기술

버클리 대학의 AMPLab에서 아파치 오픈소스 프로젝트로 2013년 시작
나중에 Databricks라는 스타트업 창업
하둡의 뒤를 잇는 2세대 빅데이터 기술
YARN등을 분산환경으로 사용
Scala로 작성됨
빅데이터 처리 관련 *다양한* 기능 제공
Spark 3.0의 구성

Spark Core
Spark SQL
Spark ML
Spark MLlib
Spark 머신러닝 라이브러리에는 2개가 있는데 하나는 Spark ML과 Spark Mlib입니다.
MLlib는 데이터 스트럭쳐 기반, ML은 데이터 프레임 기반으로 MLlib는 사라지는 단계로 앞으로 코딩을 할 일이 있다면 ML을 사용하면 됩니다.
Spark Streaming
Spark GraphX
Spark vs. MapReduce
Spark은 기본적으로 메모리 기반
메모리가 부족해지면 디스크 사용
MapReduce는 디스크 기반
MapReduce는 하둡(YARN)위에서만 동작
Spark은 하둡(YARN)이외에도 다른 분산 컴퓨팅 환경 지원 (K8s, Mesos)
MapReduce는 키와 밸류 기반 데이터 구조만 지원
Spark은 판다스 데이터프레임과 개념적으로 동일한 데이터 구조 지원
Spark은 다양한 방식의 컴퓨팅을 지원
배치 데이터 처리, 스트림 데이터 처리, SQL, 머신 러닝, 그래프 분석
Spark 프로그래밍 API
RDD (Resilient Distributed Dataset)
로우레벨 프로그래밍 API로 세밀한 제어가 가능
하지만 코딩 복잡도 증가
DataFrame & Dataset (판다스의 데이터프레임과 흡사)
하이레벨 프로그래밍 API로 점점 많이 사용되는 추세
보통 파이썬 코딩시에는 DF를, Scala 나 JAVA에는 Dataset를 사용
구조화 데이터 조작이라면 보통 Spark SQL을 사용
DataFrame/Dataset이 꼭 필요한 경우는?
- ML 피쳐 엔지니어링을 하거나 Spark ML을 쓰는 경우
- SQL만으로 할 수 없는 일의 경우
Spark SQL
Spark SQL은 구조화된 데이터 처리를 SQL로 처리
데이터 프레임을 SQL로 처리 가능
데이터프레임은 테이블처럼 sql로 처리 가능
판다스도 동일 기능 제공
초기에는 Hive 쿼리 보다 최대 100배까지 빠른 성능을 보장한다고 광고
사실은 그렇지 않음. Hive도 그 사이에 메모리를 쓰는 걸로 발전
- Hive: 디스크 -> 메모리
- Spark: 메모리 -> 디스크
- Presto: 메모리 -> 디스크
Spark ML
머신러닝 관련 다양한 알고리즘, 유틸리티로 구성된 라이브러리
Classification, Regression, Clustering, Collaborative Filtering, …
전체 리스트는 링크 참고. 딥러닝 지원은 미약
RDD 기반과 데이터프레임 기반의 두 버전이 존재
spark.mllib vs. spark.ml
- spark.mllib가 RDD 기반이고 spark.ml은 데이터프레임 기반
- spark.mllib는 RDD위에서 동작하는 이전 라이브러리로 더 이상 업데이트가 안됨
항상 spark.ml을 사용할 것!
- import pyspark.ml (import pyspark.mllib)
Spark ML의 장점
원스톱 ML 프레임웍!
데이터프레임과 SparkSQL등을 이용해 전처리
Spark ML을 이용해 모델 빌딩
ML Pipeline을 통해 모델 빌딩 자동화
MLflow로 모델 관리하고 서빙 (MLOps)
대용량 데이터도 처리 가능!
Spark 데이터 시스템 사용 예들
기본적으로 대용량 데이터 배치 처리, 스트림 처리, 모델 빌딩
예 1) 대용량 비구조화된 데이터 처리하기 (ETL 혹은 ELT)
예 2) ML 모델에 사용되는 대용량 피쳐 처리 (배치/스트림)
예 3) Spark ML을 이용한 대용량 훈련 데이터 모델 학습
Spark 데이터 시스템 사용 예 1
대용량 비구조화된 데이터 처리하기 (Hive의 대체 기술)
ETL 혹은 ELT

정제되지 않은 데이터를 Spark로 전처리한 뒤 데이터 웨어하우스에 적재하거나 다시 데이터 레이크에 적재하는 등
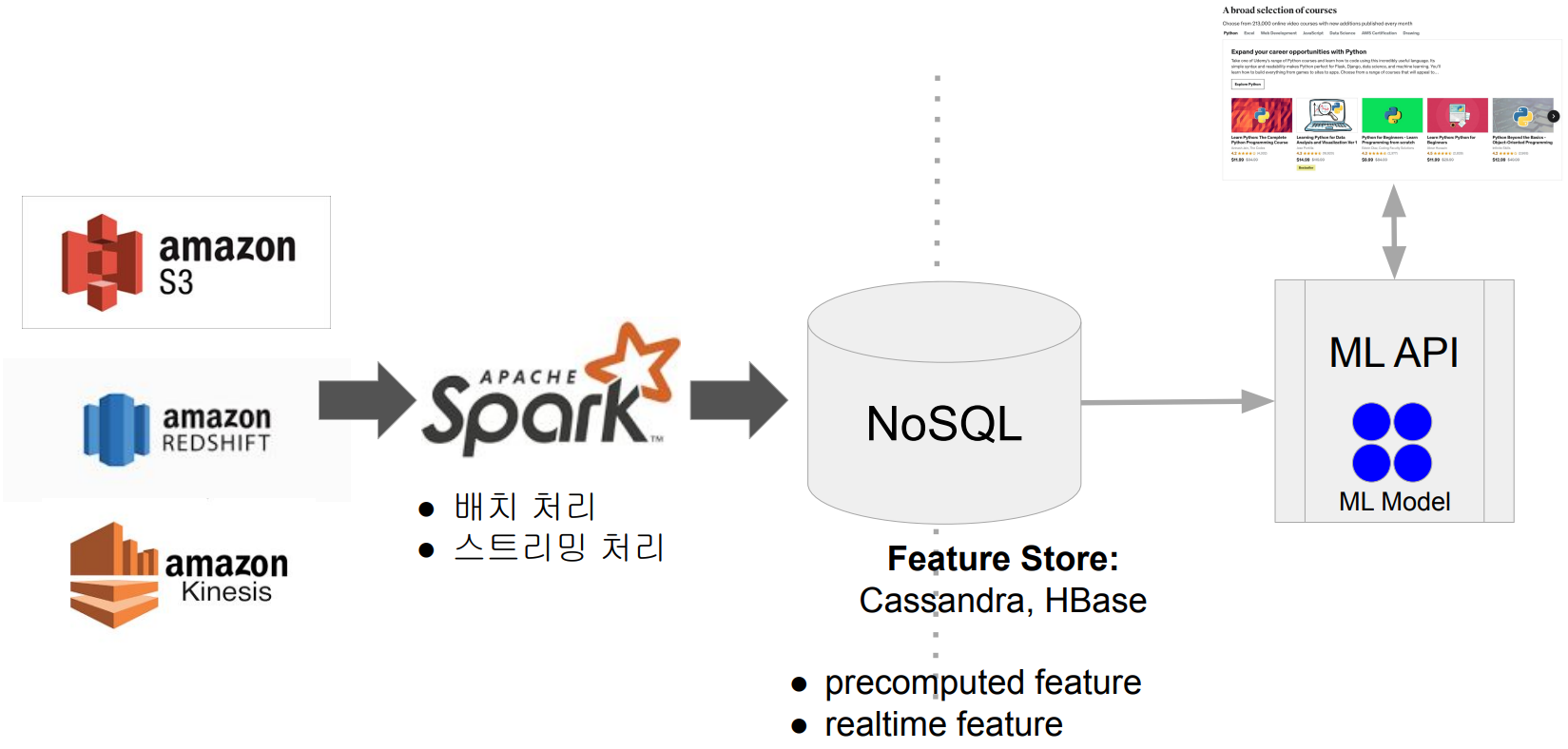
Spark 데이터 시스템 사용 예 2
ML 모델에 사용되는 대용량 피쳐 처리
이번 강의에서 사용할 Spark 환경
Spark 버전 3을 사용
Python을 사용할 예정: PySpark
Github 링크
'하둡과 Spark' 카테고리의 다른 글
| 요약 (0) | 2024.01.15 |
|---|---|
| Spark 프로그램 실행 옵션 (0) | 2024.01.15 |
| 맵리듀스 프로그래밍 실행 (0) | 2024.01.15 |
| 하둡 설치 - 맵리듀스 프로그래밍 실행 (0) | 2024.01.15 |
| 맵리듀스 프로그래밍 소개 (0) | 2024.01.15 |

