Glue 권한 추가하기
Redshift Spectrum(혹은 Athena) 사용을 위해서는 우리가 지난 시간 만든 AmazonS3FullAccess에 AWSGlueConsoleFullAccess를 하나 더 추가해야 합니다.
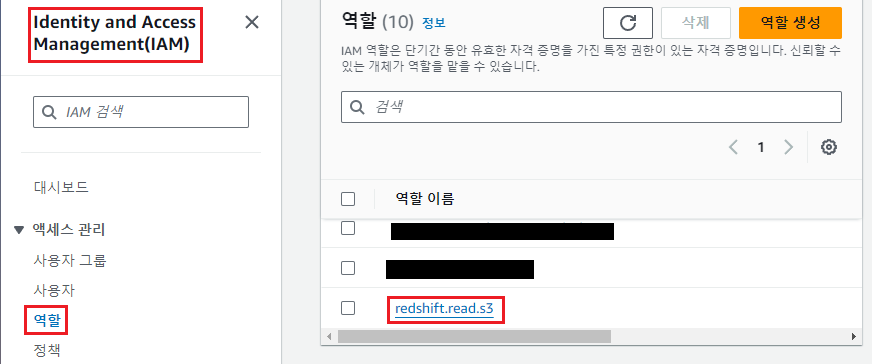
IAM의 역할에서 우리가 이전에 만든 redshift.read.s3를 클릭합니다.

지난 실습에서 만든 AmazonS3FullAccess 권한 하나만 있군요. 드랍 다운 메뉴에서 우측의 정책 연결을 클릭해주세요.

검색어를 입력한 후 체크한 뒤 권한추가를 클릭합니다.
자 IAM에서 Glue 권한을 만들었습니다. 이제 S3로 갑니다.

우리가 만든 S3 버킷으로 가주세요. 버킷 이름은 유니크하므로 여러분은 다른 이름일 것입니다.

지난 시간 만든 test_data 폴더가 보입니다. usc 폴더도 추가해주세요.

그리고 usc 폴더에 user_session_channel.csv 파일을 업로드 해주세요. 파일에 걸린 링크를 클릭하면

s3://devjon-test-bucket/usc/user_session_channel.csv
S3 URI를 확인할 수 있습니다. 이를 이용해 external table을 만들 것입니다.
사실 굉장히 작은 크기의 데이터이지만 Spectrum 학습과 실습의 취지를 위해 굉장히 큰 파일이라고 상상해주세요!
코랩 실습의 순서
코랩에서의 실습은 아래와 같은 단계로 진행됩니다.
1. 외부 테이블용 스키마 생성
2. 내부 Dimension 테이블 생성
3. 외부 Fact 테이블 생성
○ Redshift의 S3 접근용 IAM Role에 권한 추가 (AWSGlueConsoleFullAccess)
○ S3 버킷에 새 폴더 만들고 user_session_channel.csv 파일 업로드
○ 위 파일을 바탕으로 외부 테이블 생성
4. 내부 테이블과 외부 테이블 조인
Redshift Spectrum 코랩 실습
admin 계정으로 실습합니다. 혹시 jon으로 그룹 권한을 확인하고 아직도 jon으로 로그인 되었다면 admin으로 다시 Redshift에 로그인해주세요.
1. External 테이블을 보관할 스키마 생성
%%sql
CREATE EXTERNAL SCHEMA external_schema
from data catalog
database 'myspectrum_db'
iam_role '(redshift.read.s3의 arn)'
create external database if not exists;
"external_schema라는 이름의 EXTERNAL SCHEMA를 'mysepctrum_db'라는 이름의 데이터 베이스에 만들어 주는데 사용할 Role(역할)의 arn은 다음과 같다." 입니다.
2. Dimension 테이블 만들기
%%sql
CREATE TABLE raw_data.user_property AS
SELECT
userid,
CASE WHEN cast (random() * 2 as int) = 0 THEN 'male' ELSE 'female' END gender,
(CAST(random() * 50 as int)+18) age
FROM (
SELECT DISTINCT userid
FROM raw_data.user_session_channel
);
"raw_data 스키마 아래 user_property 테이블을 CTAS 방식으로 CREATE하는데 raw_data.user_session_channel테이블의 레코드들을 바탕으로 성별을 랜덤하게 지정하고 나이역시 18세에서 68세까지 랜덤하게 지정한다. userid는 하나인데 성별이 2개 나이가 여러개인 일이 없도록 DISTINCT를 붙인다." 라는 쿼리입니다.
그렇게 userid와 gender와 age컬럼을 가진 Dimension 테이블을 만듭니다.
3. Fact 테이블 만들기
%%sql
CREATE EXTERNAL TABLE external_schema.user_session_channel(
userid integer,
sessionid varchar(32),
channel varchar(32)
)
row format delimited
fields terminated by ','
stored as textfile
location 's3://devjon-test-bucket/usc/';
"external_schema 스키마에 user_session_channel이라는 테이블을 만드는데 필드는 콤마 ','로 구분되고 row format(레코드)으로 csv 한행이 레코드 한개로 정의한다. stored as textfile은 's3://devjon-test-bucket/usc/'에 저장된 모든 파일이 textfile이라는 것을 의미한다."라는 쿼리입니다.
참고로 location에서
location 's3://devjon-test-bucket/usc/user_session_channel.csv'; 처럼 파일까지 특정하면 에러가 발생합니다.
폴더내의 여러 파일들 중 한개의 파일만 point할 수 없다는 stack overflow 답변
https://stackoverflow.com/questions/42583106/how-to-point-to-a-single-file-with-external-table
location 's3://devjon-test-bucket/usc/;와 같이 폴더까지만 위치를 적어주면 usc 폴더내의 모든 폴더를 사용해 테이블을 만듭니다. 이때는 파일들 중 하나라도 포맷이 다르면(여기서는 하나의 파일이라도 csv파일이 아니라면) 에러가 발생하므로 이점 유의해주세요. 만약 usc폴더 내에 여러 파일들 중 특정한 파일 한개만 참고해 EXTERNAL TABLE을 만들고 싶다면 그 파일 한개를 다른 폴더로 분리해야 햡니다.
여기서 한가지 의문이 드실 수도 있습니다. "csv 파일의 데이터들을 직접 열어 살펴보면 userid는 순수 숫자로 이루어져 있는데 sotred as textfile로 정의하는 것이 맞나?"
예 맞습니다. csv 파일은 대개 콤마 ','로 구분된 텍스트로 간주되고 Redshift 역시 csv파일을 textfile로 간주하기 때문에 's3://devjon-test-bucket/usc/'의 모든 파일이 stored as textfile이라고 명시해야 합니다.
4. 만든 Fact 테이블과 Dimension 테이블을 JOIN해 활용하기
%%sql
SELECT gender, COUNT(1)
FROM external_schema.user_session_channel usc
JOIN raw_data.user_property up ON usc.userid = up.userid
GROUP BY 1;
'데이터 웨어하우스(Data Warehouse)' 카테고리의 다른 글
| Redshift 중지/제거하기 (0) | 2023.11.30 |
|---|---|
| Redshift ML (0) | 2023.11.30 |
| Redshift Spectrum (0) | 2023.11.29 |
| Redshift Spectrum, Athena, ML 개념 (0) | 2023.11.29 |
| 7주차 - 3 [데이터 웨어하우스] (0) | 2023.11.29 |